Chapter 1: History and Architecture of the Linux Kernel
Operating System and Kernel
In this course, we will use the following definitions:
Definition
The operating system is the set of software components that enables applications to use the underlying hardware and provides APIs to ease development.
Definition
The kernel is the set of components of the operating system that are executed in a privileged mode, usually in supervisor mode.
Kernel Taxonomy
Kernels are usually classified in various types:
Monolithic kernels
Microkernels
Hybrid microkernels
Unikernels
Let’s have a quick recap of these kernel architectures!
Monolithic Kernels
A monolithic kernel embeds all the system functionalities in a single binary. It contains all the core features of an operating system (scheduling, memory management, etc…) as well as drivers for devices or less essential components.
Characteristics
Defines a high level interface through system calls
Good performance when kernel components communicate (regular function calls in kernel space)
Limited safety: if one kernel component crashes, the whole system crashes
Examples
Unix family: BSD, Solaris
Unix-like: Linux
DOS: MS-DOS
Critical embedded systems: Cisco IOS
Why ‘monolithic’?
Monolithic means it is built as a single binary and runs in the same address space. The source code can still be organised in a modular way (e.g., using libraries).
Some monolithic kernels allow dynamic code loading as modules, e.g., for drivers. These are usually called modular monolithic kernels.
Microkernels
A microkernel contains only the minimal set of features needed in kernel space:
address-space management, basic scheduling and basic inter-process communication.
All other services are pushed in user space as servers:
file systems, device drivers, high level interfaces, etc.
Characteristics
Small memory footprint, making it a good choice for embedded systems
Enhanced safety: when a user space server crashes, it does not crash the whole system
Adaptability: servers can be replaced/updated easily, without rebooting
Limited performance: IPCs are costly and numerous in such an architecture
The hybrid kernel architecture sits between monolithic kernels and microkernels.
It is a monolithic kernel where some components have been moved out of kernel space as servers running in user space.
While the structure is similar microkernels, i.e., using user servers, hybrid kernels do not provide the same safety guarantees as most components still run in the kernel.
Controversial architecture
This architecture’s existence is controversial, as some just define it as a stripped down monolithic kernel.
A unikernel, or library operating system, embeds all the software in supervisor mode.
The kernel as well as all user applications run in the same privileged mode.
It is used to build single application operating systems, embedding only the necessary set of applications in a minimal image.
Characteristics
High peformance: system calls become regular function calls and no copies between user and kernel spaces
Security: attack surface is minimized, easier to harden
Usability: hard to build unikernels due to lack of features supported
Examples
Unikraft
clickOS
IncludeOS
Comparison Between Kernel Architectures
The choice of architecture has various impacts on performance, safety and interfaces:
Switching modes is costly: minimizing mode switches improves performance
Supervisor mode is not safe: minimizing code in supervisor mode improves safety and reliability
High level interfaces for programmers are in different locations depending on the architecture i.e., in the kernel for monolithic, but in libraries or servers for microkernels
In this course, we will focus on a monolithic modular kernel: Linux.
A Brief History of the Linux Kernel
Unix Systems
In the 1960s, MIT, AT&T Bell Labs and General Electric built Multics (Multiplexed Information and Computing Service).
Multics is a time-sharing operating system for mainframes that introduced new concepts:
multitasking: multiple users can use the system simultaneously
hierarchical file system: files are organised as a tree with directories
single-level store: files on storage are all mapped in memory, thus not accessed with read/write primitives, but through regular memory accesses
In 1970, AT&T Bell Labs left the project and started Unix, led by Ken Thompson, with Dennis Ritchie, Brian Kernighan, Douglas McIlroy, and Joe Ossanna.
Unix kept the hierarchical file system but dropped the single-level store, going for an “everything is a file” philosophy.
Unix was originally a single-tasking OS.
Why ‘Unix’?
The name Unix is a pun on Multics/Unics. Kernighan came up with the name, but states that “no one can remember” who came up with the spelling.
From: Linus Benedict TorvaldsTo: comp.os.minixSubject: What would you like to see most in minix?Date: 25 August 1991, 22:57:08Hello everybody out there using minix -I'm doing a (free) operating system (just a hobby, won't bebig and professional like gnu) for 386(486) AT clones. Thishas been brewing since april, and is starting to get ready.I'd like any feedback on things people like/dislike in minix,as my OS resembles it somewhat (same physical layout of thefile-system (due to practical reasons) among other things).I've currently ported bash(1.08) and gcc(1.40), and thingsseem to work. This implies that I'll get something practicalwithin a few months, and I'd like to know what features mostpeople would want. Any suggestions are welcome, but I won'tpromise I'll implement them :-)Linus (torv...@kruuna.helsinki.fi)PS. Yes - it's free of any minix code, and it has amulti-threaded fs. It is NOT protable (uses 386 task switchingetc), and it probably never will support anything other thanAT-harddisks, as that's all I have :-(.
Reply from Andrew Tanenbaum (creator of Minix)
From: Andrew S. TanenbaumTo: comp.os.minixSubject: What would you like to see most in minix?Date: 30 January 1992, 09:04/* blablabla */I still maintain the point that designing a monolithic kernelin 1991 is a fundamental error. Be thankful you are not mystudent. You would not get a high grade for such a design :-)/* blablabla */Prof. Andrew S. Tanenbaum (a...@cs.vu.nl)
architecture-specific code for each processor family
drivers for various hardware
Chapter 2: C Bootcamp and Kernel Programming
C Bootcamp
The Linux kernel is a C monster
By the year 2025, the Linux Kernel surpasses 40 million lines of code
Despite its size, it remains accessible because:
Strict adherence to the Linux kernel coding style
Highly structured code, resembling an object-oriented programming style
The Linux kernel is modular, allowing developers to focus on specific subsystems.
Extensive documentation is available, both in the source code and online.
A large and active community provides support and guidance.
The process of code review is rigorous and ensures high-quality contributions.
Tools like git, checkpatch.pl, and sparse help maintain code quality and consistency.
The Linux kernel is a C monster
Predominantly written in C
C Standard: C11 since version 5.18 (March 2022).
Assume GCC (version 5.1 or later, since september 2021).
Keyword
Description
#pragma GCC
Provides compiler-specific directives.
__attribute__
Modifies the behavior of functions, variables, or types.
__builtin__
Provides built-in functions for specific operations, often optimized.
__asm__
Allows embedding assembly code directly in C/C++.
__typeof__
Retrieves the type of an expression or variable.
__restrict__
Indicates exclusive use of a pointer for optimizations.
__volatile__
Prevents the compiler from optimizing an instruction or variable.
__thread
Declares a thread-local variable (Thread Local Storage).
asmlinkage
Enforces specific calling conventions for system calls.
__builtin_expect
Hints to the compiler about branch prediction.
Note
These keywords are not part of the C standard and are specific to gcc. Some of them are also available in other compilers, but their syntax may vary. The kernel can currently be compiled with Clang and ICC.
Prerequisites for this course
Before diving into the core of this vast system, in this lecture we will review or learn some advanced aspects of the C language.
However, to fully benefit from this course, you should already have a solid understanding of the basic system concepts.
C langage
The basics of C: control structures, pointers, memory allocations, …
The different segments and their functioning: .text, .rodata, .data, .bss, .stack, and .heap
The basics of compilation: preprocessor, compilation, and linking
System Programming
The system functions provided by Glibc: file handling, process management, synchronization, and more.
The concepts of address spaces, including virtual and physical addresses
The principles of interrupts and system calls
Assembly Language
The basics of assembly language: registers, instructions, …
ABI of function calls: calling conventions, stack management, …
C Bootcamp
Macro
Macros in C are preprocessor directives defined with #define, enabling text substitution before compilation.
They are invaluable for centralizing constants, simplifying code, and enhancing maintainability.
The use of macros should be completely transparent to the user. In the kernel, it is often discovered late that a function being used is actually a macro.
This poses a problem when the function-like macro is used in a conditional expression, as in the macro virtio_cread used in virtio_bt.c.
In practice, the do{}while(0) construct is often used to define empty functions in macros. This ensures that the macro behaves like a regular function, even when it does nothing. An example can be seen in the file include/linux/interrupt.h when we want to disable the hard_irq_disable function:
While macros are powerful, they can lead to unexpected behavior due to their lack of type checking and potential for side effects.
Inline functions provide a safer and more maintainable alternative in many cases.
The inline keyword allows the compiler to replace a function call by the body of the called function.
Inlined function definition
inlineint max(unsignedint a,unsignedint b){return(a > b)? a : b;}
Initial call location
int f(unsignedint y){return max(y,2* y);}
After inlining
int f(unsignedint y){return(y >2* y)? y :2* y;}
After optimisations
int f(unsignedint y){return2* y;}
How to choose between function, macro, and inline function
Simplicity and fonctionality
Criterion
Classic Function
Macro with Parameters
Inline Function
Readability and debugging
Easy to read and debug
Makes debugging harder
Easy to read and debug
Portability
Standard C
Depends on preprocessor
Depends on standard version
Types as parameters
Impossible
parameter can be a type
impossible
Safety and correctness
Criterion
Classic Function
Macro with Parameters
Inline Function
Execution Control
Always a function call
Always substituted
May or may not be inlined
Type checking
Compiler checks types
No type checking
Compiler checks types
Side-effect handling
Managed by compiler
Side effects not controlled
Managed by compiler
Optimizing Performance
Criterion
Classic Function
Macro with Parameters
Inline Function
Function call cost
Function call overhead
No call, direct substitution
No call, inlined in code
Code size
Code factorization
Multiple substitutions
Multiple Inlining
Optimization after substitution
Generic code
Contextual optimization
Contextual optimization
Register usage
Optimized by compiler
Increased register pressure
Increased register pressure
GCC-Specific Pragmas
GCC provides several pragmas to control the behavior of the compiler for specific sections of code.
Pragmas are introduced with #pragma and are often used for optimizations, warnings, or memory alignment.
Pragma
Description
#pragma once
Ensures a header file is included only once during compilation.
#pragma GCC optimize
Specifies optimization levels or flags for specific sections of code.
#pragma GCC diagnostic
Controls warnings or errors (e.g., ignore or treat as errors).
#pragma pack
Adjusts the alignment of structure members to reduce memory usage.
#pragma GCC poison
Prevents the use of specific identifiers in the code.
#pragma GCC target
Enables specific CPU instructions (e.g., SSE, AVX) for a section of code.
Warning: Pragmas are compiler-specific and may not be portable across different compilers.
GCC-Specific Attributes
To avoid name conflicts, GCC introduces a generic keyword __attribute__((...)).
Each attribute is a GCC-specific extension that allows modifying the behavior of functions, variables, and types.
Example: The noreturn attribute specifies that a function does not return, allowing the compiler to optimize accordingly.
void my_exit() __attribute__((noreturn));
Simplified usage in the kernel
The syntax of GCC attributes can be verbose, so the Linux kernel simplifies their usage with macros.
Each declaration includes links to external attribute documentation (e.g., gcc, clang).
The kernel code introduces the attributes likely() and unlikely() to improve branch prediction.
Declaration
/* * Using __builtin_constant_p(x) to ignore cases where the return * value is always the same. This idea is taken from a similar patch * written by Daniel Walker. */# ifndef likely# define likely(x)(__branch_check__(x,1, __builtin_constant_p(x)))# endif# ifndef unlikely# define unlikely(x)(__branch_check__(x,0, __builtin_constant_p(x)))# endif
A union is a special type that allows storing different types of data at the same memory location.
Each member of a union is a typed alias of the same memory location.
The allocated size is equal to the size of the largest member of the union.
union{short x;long y;float z;} my_union_t;
Examples in the kernel
Each kernel thread has its own stack.
Historically, the thread_info structure was placed at the bottom of the kernel stack.
The union overlays both in the same memory, allowing the kernel to find thread_info by masking the stack pointer.
union thread_union {struct thread_info thread_info;unsignedlong stack[THREAD_SIZE/sizeof(long)];};
Note
Today, major architectures (x86, ARM, ARM64, RISC-V, PowerPC, S390) have moved thread_info into task_struct, for security reasons: a stack overflow could corrupt thread_info and escalate privileges.
This union remains in use only on older or less maintained architectures (MIPS, SPARC, M68K, etc.).
struct page
The struct page is one of the worst union example \(\rightarrow\)
struct page {unsignedlong flags;/* Atomic flags, some possibly * updated asynchronously *//* * Five words (20/40 bytes) are available in this union. * WARNING: bit 0 of the first word is used for PageTail(). That * means the other users of this union MUST NOT use the bit to * avoid collision and false-positive PageTail(). */union{struct{/* Page cache and anonymous pages *//** * @lru: Pageout list, eg. active_list protected by * lruvec->lru_lock. Sometimes used as a generic list * by the page owner. */union{struct list_head lru;/* Or, for the Unevictable "LRU list" slot */struct{/* Always even, to negate PageTail */void*__filler;/* Count page's or folio's mlocks */unsignedint mlock_count;};/* Or, free page */struct list_head buddy_list;struct list_head pcp_list;};/* See page-flags.h for PAGE_MAPPING_FLAGS */struct address_space *mapping;union{ pgoff_t index;/* Our offset within mapping. */unsignedlong share;/* share count for fsdax */};/** * @private: Mapping-private opaque data. * Usually used for buffer_heads if PagePrivate. * Used for swp_entry_t if PageSwapCache. * Indicates order in the buddy system if PageBuddy. */unsignedlong private;};struct{/* page_pool used by netstack *//** * @pp_magic: magic value to avoid recycling non * page_pool allocated pages. */unsignedlong pp_magic;struct page_pool *pp;unsignedlong _pp_mapping_pad;unsignedlong dma_addr; atomic_long_t pp_ref_count;};struct{/* Tail pages of compound page */unsignedlong compound_head;/* Bit zero is set */};struct{/* ZONE_DEVICE pages *//** @pgmap: Points to the hosting device page map. */struct dev_pagemap *pgmap;void*zone_device_data;/* * ZONE_DEVICE private pages are counted as being * mapped so the next 3 words hold the mapping, index, * and private fields from the source anonymous or * page cache page while the page is migrated to device * private memory. * ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also * use the mapping, index, and private fields when * pmem backed DAX files are mapped. */};/** @rcu_head: You can use this to free a page by RCU. */struct rcu_head rcu_head;};union{/* This union is 4 bytes in size. *//* * For head pages of typed folios, the value stored here * allows for determining what this page is used for. The * tail pages of typed folios will not store a type * (page_type == _mapcount == -1). * * See page-flags.h for a list of page types which are currently * stored here. * * Owners of typed folios may reuse the lower 16 bit of the * head page page_type field after setting the page type, * but must reset these 16 bit to -1 before clearing the * page type. */unsignedint page_type;/* * For pages that are part of non-typed folios for which mappings * are tracked via the RMAP, encodes the number of times this page * is directly referenced by a page table. * * Note that the mapcount is always initialized to -1, so that * transitions both from it and to it can be tracked, using * atomic_inc_and_test() and atomic_add_negative(-1). */ atomic_t _mapcount;};/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */ atomic_t _refcount;#ifdef CONFIG_MEMCGunsignedlong memcg_data;#elif defined(CONFIG_SLAB_OBJ_EXT)unsignedlong _unused_slab_obj_exts;#endif/* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */#if defined(WANT_PAGE_VIRTUAL)void*virtual;/* Kernel virtual address (NULL if not kmapped, ie. highmem) */#endif /* WANT_PAGE_VIRTUAL */#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGSint _last_cpupid;#endif#ifdef CONFIG_KMSAN/* * KMSAN metadata for this page: * - shadow page: every bit indicates whether the corresponding * bit of the original page is initialized (0) or not (1); * - origin page: every 4 bytes contain an id of the stack trace * where the uninitialized value was created. */struct page *kmsan_shadow;struct page *kmsan_origin;#endif} _struct_page_alignment;
Structures in Memory
A structure is a collection of one or more variables.
struct version {unsignedshort major;// usually 2 bytesunsignedlong minor;// usually 8 byteschar flags;// 1 byte};
Memory alignment
A memory access is aligned if the accessed address is a multiple of the size of the access.
Example: an access to an unsignedlong is aligned if the address is a multiple of 8 bytes.
Ordering and Padding - GCC has significant freedom in arranging structure members in memory, but:
The memory order of members always follows their declaration order
By default, each member is aligned to its size
For a given configuration (architecture, ABI, compiler options and attributes), the layout is always the same
The programmer can reorder fields to minimise padding:
struct version {unsignedlong minor;// usually 8 bytesunsignedshort major;// usually 2 byteschar flags;// 1 byte};
Type Sizes Depend on Architecture & OS
The size of primitive types, and therefore structures, varies across architectures and operating systems.
struct version {unsignedshort major;// usually 2 bytesunsignedlong minor;// 4 bytes or 8 byteschar flags;// 1 byte};
Size in Bytes of : unsignedlong
Architecture
Linux (LP64)
Windows (LLP64)
macOS (LP64)
x86-32
4
4
4
x86-64
8
4
8
ARM32
4
4
-
ARM64
8
4
8
Size in Bytes of : struct version
Architecture
Data
Linux
Windows
macOS
x86-32
7
12
12
12
x86-64
11 / 7
24
12
24
ARM32
7
12
12
-
ARM64
11 / 7
24
12
24
Packing Structures
Padding wastes memory, especially in arrays of structures or frequently allocated objects.
GCC provides two ways to compact a structure by removing padding, with attribute or pragma directive.
The Linux kernel also defines its own macro for this in linux/compiler_attributes.h.
False sharing occurs when two CPUs access different variables that share the same cache line, causing unnecessary cache invalidations and performance degradation.
Tip
In the kernel, use the macros __aligned(n) and ____cacheline_aligned:
If you need to print information to be available from user space, e.g., tracing or debugging, you can use the printk() function.
It works similarly to printf(), with a couple of differences:
You should prefix your format string with a priority level defined by macros in include/linux/kern_levels.h, from KERN_EMERG to KERN_DEBUG.
The output doesn’t go to stdout, but in the kernel ring buffer that you can read from user space with the dmesg command, or with journalctl (and other commands)
Example:
printk(KERN_ERR "%s:%d: this shouldn't be reached...\n", __FILE__, __LINE__);
If you need to wait for a resource (e.g., network packet, message), the interface should implement a wait queue to allow your thread to sleep and be woken up when the resource is available.
wait_event(wait_queue, condition);
wait_event_interruptible(wait_queue, condition);
thread sleeps and will be woken up if wake_up() is called on the wait queue and the condition is true
same as wait_event(), but the thread can also be woken up by a signal
The resource handler calls wake_up() on the queue to wake up waiting threads.
Workqueues
Workqueues allow you to execute code asynchronously.
At creation time, a pool of thread is initialised.
Jobs can then be submitted in the form of a function pointer and a pointer to an argument.
A thread from the workqueue will, asynchronously, check the queue, pop a job and execute it.
Tip
Documentation available in Documentation/core-api/workqueue.rst.
Generic Data Structures
The kernel also offers generic data structures to work with:
Linked lists
Maps
Circular buffers
Red-black trees
…
Important
Generic data structures in C are not obvious to build…
Generic Data Structures in C
Instead of having objects in a list, we have the list in the objects!
You only need one list_head type to be defined, and you can reuse it for any object type!
When you iterate over the list, how do you get the containing object?
Container of
From the address of any member in a structure, how can we get the address of the structure? e.g., from the address of a list_head element in a structure
Linux implements the container_of macro!
/** * container_of - cast a member of a structure out to the containing structure * @ptr: the pointer to the member. * @type: the type of the container struct this is embedded in. * @member: the name of the member within the struct. * * WARNING: any const qualifier of @ptr is lost. */#define container_of(ptr, type, member)({\void*__mptr =(void*)(ptr);\static_assert(__same_type(*(ptr),((type *)0)->member)||\ __same_type(*(ptr),void),\"pointer type mismatch in container_of()");\((type *)(__mptr - offsetof(type, member)));})
You can find similar helpers for all generic data structures.
Go check them out in the kernel sources!
Concurrency in the Kernel
Resources/objects can be accessed concurrently in the kernel.
There are two reasons this can happen:
Preemption: Since version 2.6, the Linux kernel is preemptible.
This means that kernel code can be interrupted by higher priority code, e.g., device interrupt.
Multi-core processors: With multi-core CPUs, two threads can execute kernel code in parallel, and thus access the same kernel data concurrently.
Possible solutions:
Mask interrupts
Big Kernel Lock
Synchronisation primitives: semaphores, spinlocks
Atomic operations
Masking Interrupts
Concurrency problems can arise due to preemption both on single- and multi-core systems.
In the case of single-core CPUs, it can be solved solely by disabling interrupts, making the kernel code non-preemptible.
In Linux, you can use the following macros:
local_irq_disable(): this uses the proper assembly instruction to disable interrupts on the current core, e.g., cli on x86.
local_irq_enable(): this uses the proper assembly instruction to enable interrupts on the current core, e.g., sti on x86.
Example: A driver for a joystick in drivers/input/joystick/analog.c
staticint analog_cooked_read(struct analog_port *port){/* some code */ local_irq_disable(); this = gameport_read(gameport)& port->mask; now = ktime_get(); local_irq_restore(flags);/* some code */}
Big Kernel Lock
On multi-core systems, disabling interrupts is not sufficient, as other cores might also access data concurrently.
One potential solution is to serialise all kernel code, allowing only one thread at a time to execute code in supervisor mode.
This was the initial solution used in Linux when support for multi-core CPUs was added.
The Big Kernel Lock (BKL) was taken when entering the kernel and released when exiting.
Only one thread at a time was running kernel code.
Pro: Extremely simple to implement and safe
Con: Large performance degradation due to the loss of parallelism for kernel code
Linux and the BKL
Linux had a Big Kernel Lock from the introduction of Symmetric Multi-Processor (SMP) in version 2.0 in 1999 until its removal in 2.6.39 in 2011.
Synchronisation Primitives
Since the BKL removal, fine-grained synchronisation mechanisms are used in the kernel.
A non-exhaustive list of synchronisation mechanisms and their (partial) API:
Most of these have variations that also disable interrupts when taking a lock.
Atomic Operations
Concurrent access problems can also be solved by using atomic operationsin some cases.
Atomic operations are architecture-specific, and are defined in include/linux/atomic/atomic-instrumented.h
These operations should be used on a specific type, atomic_t, to represent the atomic variable.
You can find the usual atomic operations, for example:
void atomic_add(int i, atomic_t *v);
void atomic_dec(atomic_t *v);
void atomic_or(int i, atomic_t *v);
And many others…
Coding Style
The Linux Kernel Coding Style
Defined in Documentation/process/coding-style.rst.
It defines a set of rules that will be enforced when a patch is submitted:
Indentation
Line length
Spaces and braces
Error management
etc.
Tip
You can check if your patches are valid with regard to the coding style with the scripts/checkpatch.pl script!
Some Coding Style Rules
Indentation
Indentation is done with tabs, not spaces.
Tabs are 8 characters long.
Line length
For better readability, the preferred limit on the length of a line is 80 characters.
However, never break user-visible strings, as it also breaks the ability to grep them.
Since 2020, checkpatch.pl only complains about lines longer than 100 characters.
Too restrictive?
From the coding style documentation:
Now, some people will claim that having 8-character indentations makes the code
move too far to the right, and makes it hard to read on a 80-character terminal
screen. The answer to that is that if you need more than 3 levels of
indentation, you're screwed anyway, and should fix your program.
Some Coding Style Rules (2)
Braces
Opening braces are on the same line as the block they open, except for functions where they are on the next line
Closing braces are alone on an empty line
Don’t use braces to surround single-line statements…
… except if another branch of a conditional has multiple statements
for(int i =0; i <10; i++){ printk("%d\n", i);}
int inc(int x){return++x;}
if(!x) x++;
if(x > y) y++;else x++;
if(x > y){ y++;}else{ x++; y--;}
Some Coding Style Rules (3)
Spaces
Philosphy of function-versus-keyword usage.
No spaces after functions
Spaces after keywords (except if they are used like function, e.g., sizeof)
if, switch, case, for, do, while
For operators:
Spaces on both sides of binary and ternary operators
= + - < > * / % | & ^ <= >= == != ? :
No space after unary operators or before/after postfix/prefix increment and decrement
& * + - ~ ! ++ –
No space around structure member operators
. ->
No trailing spaces at the end of lines
Chapter 3: Implementing Kernel Modules
A Quick Tour of the Kernel Configuration and Build System
Getting the Sources
From the official kernel website, kernel.org, download the tarball archive.
You can (and should) also check out the integrity of the tarball with the PGP signature:
$ wget https://cdn.kernel.org/pub/linux/kernel/v6.x/linux-6.5.7.tar.sign $ unxz linux-6.5.7.tar.xz # the signature is done on the decompressed tarball $ gpg –verify linux-6.5.7.tar.sign linux-6.5.7.tar
This will probably fail because you don’t have the public keys of the maintainers that generated the tarball.
Get them from the kernel’s key server (documentation):
The kernel configuration describes the features that will be enabled in the built binary, as well as change their behavior.
It also describes if features should be built-in the binary or compiled as modules.
By default, the Makefile-based build system uses the file .config located at the root of the kernel sources.
You can generate initial configurations with the following commands (non-exhaustive list):
make allnoconfig : minimal, everything that can be disabled is disabled
make defconfig : default configuration for the local architecture
make localmodconfig : configuration based on the current state of the machine (plugged devices, etc.) and builds them as modules
make localyesconfig : same but everything is built-in
make oldconfig : keeps the values of the current .config and asks for the new options
Or you can copy the configuration of your running kernel:
$ cp /boot/config-$(uname -r)* .config # available on some distros $ zcat /proc/config.gz > .config # available if CONFIG_IKCONFIG_PROC is enabled
If you need to know more about your hardware to generate your config, check out these commands:
lshwd, lscpu, lspci, lsusb, …
cat /proc/cpuinfo, cat /proc/meminfo, …
dmidecode, hdparm
dmesg
Building the Kernel
The kernel build system is based on Makefiles.
Just run make to compile it.
$ time make real 80m15.486s user 74m54.606s sys 5m32.300s
Compilation can take a long time, so do it in parallel!
$ make -j $(nproc)
The compilation produces the following important files:
vmlinux: the raw Linux kernel image. This ELF is used for debugging and profiling;
System.map: symbol table of the kernel. Not necessary at run time, used for debugging;
arch/<arch>/boot/bzImage: compressed image of the kernel. This is the one that will be loaded and used.
$ du -sh vmlinux arch/x86/boot/bzImage 49M vmlinux 13M arch/x86/boot/bzImage
You can get some info on the image with the file command:
$ file arch/x86/boot/bzImage arch/x86/boot/bzImage: Linux kernel x86 boot executable bzImage, version 6.5.7-lkp (redha@wano) #2 SMP PREEMPT_DYNAMIC Thu Oct 19 16:05:37 CEST 2023, RO-rootFS, swap_dev 0XC, Normal VGA
Installing a Kernel
Two main steps:
1. Install the kernel image, the symbol map and the initrd
$ make install
This will copy the image and symbol map in /boot, and generate the initramfs.
2. Install the modules
$ make modules_install
This will copy the modules (.ko files) into /lib/modules/<version>.
About the Symbol Map
The symbol map (System.map) provides the list of the symbols available in this kernel, their address and type.
$ head System.map 0000000000000000 D __per_cpu_start 0000000000000000 D fixed_percpu_data 0000000000001000 D cpu_debug_store 0000000000002000 D irq_stack_backing_store 0000000000006000 D cpu_tss_rw 000000000000b000 D gdt_page 000000000000c000 d exception_stacks 0000000000014000 d entry_stack_storage 0000000000015000 D espfix_waddr 0000000000015008 D espfix_stack
Check the manpage of the nm program for an explanation of the types.
As a rule of thumb (mostly true), lowercase means local scope while uppercase means global scope (i.e., exported symbol).
Linux Init Process
Back to the Lab
In Lab 2, task 3, you were asked to replace the init binary by a hello_world program, which led to a kernel panic. Why?
Roles of init
Initialise the system: start daemons/services, manage user sessions, mount partitions, etc.
Ancestor of all the processes on the system
Adopt all orphaned processes
Characteristics of init
Has PID 1
Cannot die
Demo time!
Linux Kernel Modules
Development Infrastructure
Multiple development methods:
Local setup
Use your usual development software, compile and run your new modules/kernel on your machine. Pros: easy, quick Cons: if a crash occurs, you can do nothing
Remote machine
If you have access to a separate testing machine, you can do your development on your machine and test remotely to avoid the crash issues.
This machine is usually hooked through network/serial to the development machine to allow remote debugging and monitoring. Pros: good development setup, robust to crashes Cons: not always possible to have a second machine
Virtual machine
Develop on your local setup and deploy on a virtual machine.
This replaces the previous method well, while being faster to use, and doesn’t require a second machine. Pros: good development setup, robust to crashes, single machine Cons: doesn’t always perfectly capture real hardware, might be slow depending on the host and guest machines
In this course, we will use the last method with QEMU as a hypervisor.
Kernel Modules Interface
A module is a library dynamically loaded into the kernel. It triggers a call to a registered function when loaded and when unloaded.
The kernel provides two macros to register these functions: module_init() and module_exit().
For these to work, you will need some header files included:
// contains the module API#include <linux/module.h>/// contains the init and exit macros#include <linux/init.h>/// if needed: base types, functions, macros...#include <linux/kernel.h>
Module Information
You should also add some information about your module with some pre-defined macros, usually at the beginning of the file:
MODULE_DESCRIPTION("Hello world module");MODULE_AUTHOR("Redha Gouicem, RWTH");MODULE_LICENSE("GPL");
The __init and __exit annotations are used to help the compiler optimize the memory usage.
When some module is statically built-in the kernel binary, functions tagged with these annotations are placed in specific segments:
.init.text that is freed after the boot of the kernel
.exit.text that is never loaded in memory
Building a Module
The running kernel is deployed with a generic Makefile located in /lib/modules/$(uname -r)/build.
You can use it from anywhere like this:
$ make -C /lib/modules/$(uname -r)/build M=$PWD
This will generate your module as a .ko file (kernel object).
You can also use a custom Makefile like this one as a wrapper:
#include <linux/init.h>#include <linux/module.h>#include <linux/moduleparam.h>staticchar*month ="January";module_param(month, charp,0660);staticint day =1;module_param(day,int,0000);staticint __init hello_init(void){ pr_info("Hello ! We are on %d%s\n", day, month);return0;}module_init(hello_init);staticvoid __exit hello_exit(void){ pr_info("Goodbye, cruel world\n");}module_exit(hello_exit);
With default values:
$ insmod hello.ko $ dmesg [180525.067016] Hello ! We are on 1 January
With parameters:
$ insmod hello.ko month=December day=31 $ dmesg [181086.216097] Hello ! We are on 31 December
Kernel Dynamic Linker
Like shared libraries, modules are dynamically loaded: they only have access to symbols explicitly exported to them!
By default, they have access to absolutely no variable or function from the kernel, even if they are not static!
Two macros allow to explicitly export symbols to modules:
EXPORT_SYMBOL(s) makes the symbol s visible to all loaded modules
EXPORT_SYMBOL_GPL(s) makes the symbol s visible to all modules with a license compatible with GPL (according to their MODULE_LICENSE)
Example: using the pm_power_off() function exported in arch/x86/kernel/reboot.c and available on my system:
$ grep pm_power_off /lib/modules/$(uname -r)/build/System.map ffffffff810ed2f0 t legacy_pm_power_off ffffffff8274d7d8 r __ksymtab_pm_power_off ffffffff838a47f8 B pm_power_off
#include <linux/module.h>#include <linux/kernel.h>MODULE_DESCRIPTION("Power off module");MODULE_LICENSE("GPL");staticint __init devil_init(void){ pr_info("The end is nigh...\n");if(pm_power_off) pm_power_off();return0;}module_init(devil_init);
Module Dependencies
If a module X uses at least one symbol from module Y, then Xdepends onY.
Dependencies are not explicitly defined: they are automatically inferred during the kernel/module compilation.
You can find the list of dependencies in the file /lib/modules/<version>/modules.dep.
This file is generated by the depmod program, who checks which symbols are used by a module, and which module provide these symbols.
You can also check the dependencies of a module with modinfo.
Automated dependency solving
Obviously, modules must be inserted in the proper order: if X depends on Y, Y needs to be inserted before X.
If you are using modprobe, it will automatically insert dependencies first.
This is also true for unloading modules (in the reverse order).
Contributing to the Kernel
Patch or Module?
When developing something in the kernel, the first design choice is “how?”
You have two choices:
Implement your code in the kernel through a patch
Your code is then statically built-in the kernel binary
Implement your code in a module
Your code can be dynamically loaded by the kernel at run time
Whenever possible, modules are the best choice, as they have more chances to be merged in the mainline.
Modules: Pros and Cons
While using modules should be your first choice, it also has some drawbacks depending on what you are doing.
Pros:
Easier to develop
Easier to distribute
Avoids overloading the kernel
Lower chances of conflicts
Cons:
Internal kernel structures cannot be modified e.g., adding a field to the file descriptor structure
Replacing/changing the behaviour of an existing kernel function e.g., change the page frame allocator code
Patching the Kernel
If you need to modify the kernel and distribute your changes, you most likely will use patches.
A patch is the result of the diff command applied on the original files and your modified version.
It contains all the data for the patch to automatically apply the changes.
diff: Compares files line by line
Shows the added/modified/removed lines
Can ignore tabs/spaces
Can compare whole directory trees (-r)
patch: Apply changes to existing files
Can apply a patch on a file passed as an argument or stdin
Can apply a patch on a directory tree
Creating and Applying a Patch
Creating a patch for the kernel tree:
-r to enable recursive patch
-u to use the unified diff format (more compact and easier to read)
When you think your code is ready for review by the kernel maintainer, you need to send it to them!
Note: This is just an overview of the process!
Ready your code for public eyes
Test your code first to avoid silly bugs (and being fun of publicly)
Make sure that your code is compliant with the kernel coding style and is understandable (comments?)
Use tools to helps you, e.g., checkpatch, clang-format
Prepare your patch(es)
Choose against which version of the kernel to generate your patches, usually the current mainline from Linus’ git tree (a -stable or -rc release)
Split your submission into a set of patches/commits, each being logically independent, and able to be built and run
You can manually create the patches with diff or use git format-patch to automatically generate patches from your commits (assuming you used git in the first place)
Submitting Your Work to the Kernel Community (2)
Format your patch series for emailing
Each patch email should have a one-line short description, followed by blank line and a multi-line long description, then a list of tag lines specifying who co-authored, reviewed the patch, etc. Finally, the patch should be appended.
All of this can be fairly well automated with git format-patch
Send your patch series to the mailing list
Find out to which mailing list and maintainers the email should be sent to, using the scripts/get_maintainer.pl script on your patch. You should also CC anyone who might need to see this, e.g., they work on something similar
You might need to write a first summary email (a cover letter) for your patch series
This can be fairly well automated with git send-email
The emails need to be written in plain text, no HTML!
Goal: Store information about subsystems, hardware devices, drivers, …
This should be the default choice!
Advantages:
Hierarchical topology, information is arranged logically, by subsystem, component, etc…
Provides a set of mechanisms to free memory and recursively destroy directories
Cons:
More complex than procfs
Each file represents one single piece of data
A piece of data cannot be larger than one page (PAGE_SIZE)
sysfs: Directories
The struct kobject is at the heart of the sysfs:
Each directory corresponds to a kobject
A file in the sysfs is not a kobject
Most important fields:
struct kobject {constchar*name;// name of the directorystruct kobject *parent;// kobject of the parent directorystruct kset *kset;// the collection of kobjects this object belongs tostruct kref kref;// reference counter, used to free the memory properlyconststruct kobj_type *ktype;// type of the object, with functions pointers to manipulate it/* ... */};
To create a kobject and add it to the sysfs, you can use this functions:
This works for simple cases (most likely what you want to do). For more complex scenarios, there are other functions to initialize, create and register kobjects. Check out the documentation for more information!
Don’t forget to cleanup your kobjects and their files when they are not needed anymore with:
void kobject_put(struct kobject *kobj);
sysfs: Files
Kobject attributes
Each file in the sysfs corresponds to one single value and is associated with an instance of a struct kobj_attribute.
We want to export the state of our system represented by an int system_enabled global variable in a human-readable form in the file located at /sys/kernel/my_state/system_enabled.
configfs is another ram-based file system offering the converse functionality to sysfs, mounted in /sys/kernel/config.
While the sysfs is a view of kernel objects, configfs is a manager of kernel objects, i.e., it allows to create/destroy kernel objects from user space.
Example: Allowing user programs to create and configure a virtual network devices by doing an mkdir in the configfs directory of a driver.
Advantage:
Allows user space programs to manage kernel objects
Drawbacks:
Complex to set up
One file equals one value
debugfs
The debugfs offers a very flexible and simple API targeted at simplifying kernel development and debugging.
System calls are a software interrupt like the others:
1. Place the system call number in a register
2. Place the arguments in the proper registers and/or on the stack
3. Trigger the “system call” interrupt (switching to supervisor mode)
4. Jump to the “system call” interrupt handler
5. Load the system call table and jump to the index given by the syscall number
6. Execute the system call handler
7. Return the result to user space (switching back to user mode)
System Calls: The Instruction Way
Some architectures provide a specific instruction (syscall, svc, sysenter, …):
1. Place the system call number in a register
2. Place the arguments in the proper registers and/or on the stack
3. Use the system call instruction (switching to supervisor mode)
4. Jump to the index given by the syscall number in the syscall table
5. Execute the system call handler
6. Return the result to user space (switching back to user mode)
One level of indirection is bypassed!
Tip
You can find a very detailed (with less omissions) explanation of how system calls work in Linux here!
System Calls: The Linux Application Binary Interface
API:Application Programming Interface
High-level interface for programmers (function prototypes, data types, …)
ABI:Application Binary Interface
Low-level interface for compilers/OS (calling conventions, architecture-specific)
Architecture
syscall#
retval
arg1
arg2
arg3
arg4
arg5
arg6
arg7
Arm EABI
r7
r0
r0
r1
r2
r3
r4
r5
r6
arm64
w8
x0
x0
x1
x2
x3
x4
x5
mips
v0
v0
a0
a1
a2
a3
a4
a5
riscv
a7
a0
a0
a1
a2
a3
a4
a5
x86-64
rax
rax
rdi
rsi
rdx
r10
r8
r9
How do we add a system call to Linux?
We’ll see that a bit later, when you’ll need to do it for an exercise.
ioctl
ioctls are a way to provide custom system calls, mainly for device drivers.
They are called from user space by the ioctl system call and provide an additional level of indirection, with each ioctl having a number.
Advantages:
Easy to extend
Provide a syscall-like interface, i.e., an arbitrary function call
Drawback:
Numbers have to stay “forever”, as changing them might break existing user space applications
An ioctl is tied to a file. It is registered as a file operation similar to read or write in the kernel.
For a given device, each ioctl has a number generated through a set of macros.
How can we use ioctls?
We won’t see the API in details here, you will have a task solely on that in the next lab.
Sockets
The kernel also provide a socket-based interface with user space called netlink.
It is similar to regular sockets in user space, but with the AF_NETLINK socket family.
Advantage:
Symmetrical communication
Drawback:
Implementation is a bit more complex than simple read/write semantics
Chapter 5: Memory Management
Memory Organization
Pages are the basic unit of memory management.
Even if memory is byte/word addressable, the smallest management unit is the page, to accommodate fast lookups and address translations.
Some definitions:
A page (or virtual page) is a fixed-size block of contiguous virtual memory.
A page frame (or physical page) is a fixed-size block of contiguous physical memory.
Page size depends on the architecture, some of them even support multiple sizes.
Supported page sizes (non-exhaustive)
Architecture
4 KiB
16 KiB
64 KiB
2 MiB
4 MiB
32 MiB
512 MiB
1 GiB
x86_64
X
X
X
armv7
X
X
aarch64
X
X
X
X
X
X
X
riscv32
X
X
riscv64
X
X
X
Kernel Representation of Pages Frames
The kernel maintains a struct page for each page frame available on the system.
The structure is defined in include/linux/mm_types.h.
Here is a simplified definition of the structure:
struct page {unsignedlong flags;// page status, flags available in include/linux/page-flags.h atomic_t _refcount;// number of references to this frame/* page cache and anonymous pages */ atomic_t _mapcount;// number of page tables this frame is mapped instruct address_space *mapping;// if used in page cache, object associated to this framestruct list_head lru;// least-recently used list for evictionvoid*virtual;// kernel virtual address when not kmapped, used when using high memory};
Since there is one struct page per physical page, isn’t this a lot of memory for metadata?
In practice, a struct page is only around 40 bytes (lots of unions in there).
So, in a system with 16 GiB of memory and 4KiB pages, you will have: \(\frac{17,179,869,184}{4,096} = 4,194,304\) pages.
Which means only\(4,194,304~\text{pages} \times 40~\text{B} = 160~\text{MiB}\), or roughly 1% of the total memory.
You can reduce this metadata footprint by increasing the page size, i.e., using huge pages.
Zones
Not all addresses are equal in hardware, so all frames are not treated identically.
The kernel separates pages in multiple zones with different properties.
The two main hardware limitations that require zones are:
Some hardware can only do Direct Memory Accesses (DMA) to certain addresses
Some architectures have a physical address space larger than their virtual address space,
which means that some frames are not permanently mapped into the kernel address space
Zones on x86-32 (from Linux Kernel Development, 3rd Edition, Robert Love)
Zone
Description
Physical Memory
ZONE_DMA
Contains frames that can be accessed through DMA
\(\lt\) 16 MiB
ZONE_NORMAL
Permanently mapped pages (DMA also possible)
16–896 MiB
ZONE_HIGHMEM
Memory not permanently mapped into the kernel’s address space
\(\gt\) 896 MiB
64-bit architectures
On architectures that can address large address spaces, e.g., 64-bit, ZONE_HIGHMEM usually does not exist, and all memory is split between ZONE_DMA and ZONE_NORMAL.
Memory API
Quick recap of the memory management API in the kernel:
Allocate pages
struct page *alloc_pages(gfp_t gfp_mask,unsignedint order);// allocate 2^order contiguous physical pages, return the first pagevoid*page_address(struct page *page);// get the actual address of the page from it's struct pageunsignedlong __get_free_pages(gfp_t gfp_mask,unsignedint order);// same as alloc_pages(), but returns the address directlystruct page *alloc_page(gfp_t gfp_mask);// wrapper to allocate a single pageunsignedlong __get_free_page(gfp_t gfp_mask);// wrapper to allocate a single page and get the actual addressunsignedlong get_zeroed_page(gfp_t gfp_mask);//same as __get_free_page(), but the page is filled with zeros
You might have noticed that most of the memory API works at the page granularity.
There are multiple levels of allocators:
User space allocators that allocate objects of arbitrary sizes, request memory from the kernel e.g., glibc malloc, jemalloc, more implementations here
Kernel space object allocators that allocate objects of arbitrary sizes, request page frames
Page frame allocator that allocates page frames from the physical memory
The page frame allocator is responsible for managing the physical memory, giving page frames to allocators upon request, and reclaiming them when freed.
Page order
You might have also noticed that the page granularity API uses orders (powers of two) for allocations:
Orders come from the inner working of the page frame allocator of Linux: the buddy allocator.
Buddy Allocator
Linux uses the buddy allocator to manage physical page frame allocation.
Initially, physical memory is seen as a single large chunk containing all page frames, e.g., \(2^8 = 256\) pages.
Allocation:
The allocation size is rounded to the next power of 2, i.e., the order
A chunk of the closest size is repeatedly split in half until it reaches the order size Two chunks split from the same parent are called buddies
The resulting chunk is allocated
If a chunk of the correct size is available, it is directly chosen
Free:
The freed chunk is tagged as free
If two buddies are free, they are merged back into a larger chunk
If two neighbors are free but not buddies, they cannot be merged!
Buddy Allocator: Linux Implementation
Linux implements the buddy allocator with an array of free lists, indexed by order.
Examples:
alloc_pages(GFP_KERNEL,3);
Look up the list of order 3 for a free chunk
A chunk is available, remove it from the free list and return it to the caller
alloc_pages(GFP_KERNEL,4);
Look up the list of order 4 for a free chunk
No chunk of order 4 available, look up for a higher order free chunk
A chunk of order 5 is available: split it, choose one chunk for allocation and put the other in the order 4 free list
When freeing a chunk of size order, it is added back its free list.
The kernel also maintains bitmaps to identify buddies: if both buddies are free, they are merged and stored in the order + 1 list.
User interface via procfs
You can check the state of your buddy allocator by reading the /proc/buddyinfo file.
Object Allocators
The page frame allocator works at the page granularity.
This is not convenient for most allocations that request memory for smaller objects!
Object allocators act as a layer between the page allocator and subsystems to allocate smaller chunks of memory. They allocate pages, and “redistribute” smaller chunks to subsystems that allocate memory through them.
For example, when using kmalloc(), you are using an object allocator, not directly allocating pages.
Linux has multiple object allocation layers (you can even implement your own), but we will see the main one: the slab layer.
The Slab Layer
Allocating and freeing objects is extremely frequent, so it’s a good idea to have some sort of caching mechanism.
In Linux, this caching mechanism is called the slab layer.
The slab layer allows you to create caches, each of which contains a certain type of objects, e.g.,struct task_struct or struct inode.
Each cache is then divided into slabs, blocks of contiguous memory that contain a certain number of instances of the object stored by this cache.
A slab contains the actual data and maintains their status (used or free).
When a slab is full, the slab layer will allocate a new one for this cache.
When the system wants to reclaim memory, empty slabs will be freed.
Note
Additionally, allocations are done at the page granularity, so for smaller objects, you would need manual management to not waste memory.
SLAB Allocator
Added in Linux in 1996, implements work from Sun Microsystems in SunOS 5.41
Cache friendly
Queues to track per-cpu and per-node data
Page coloring to enforce cache locations
NUMA aware
Per-node slabs, allocation are done on the local node by default
Other policies can be used depending on the objects stored
Design: Page frame layout
Metadata of each slab can be embedded in the slab itself:
freelist contains the indexes of the free objects in this slab. It has as many entries as the number of objects that can be stored in the page frame
padding aligns the objects properly
Note
Multiple allocations can be done by only touching one cache line (the one with the freelist). No need to touch the actual objects.
SLAB Allocator (2)
Design: Data structures
Partial description, see their real definitions for more details
struct kmem_cache_node {struct list_head slabs_partial;// slabs with free objectsstruct list_head slabs_full;// full slabsstruct list_head slabs_free;// empty slabs/* some counters, locks, and pointers to array_caches */};
struct array_cache {unsignedint avail;// number of active entriesunsignedint limit;// max number of entriesvoid*entry[];// LIFO array of free elements};
struct slab {/* metadata */struct kmem_cache *slab_cache;struct list_head slab_list;void*freelist;void*s_mem;/* ... *//* actual data, containing the page frame layout shown here*/};
Frame layout:
Object layout:
SLUB Allocator
Introduced in 2007. The idea is to simplify the implementation, with less queues.
Locality by having per-cpu slabs, still NUMA aware
As seen previously, the “main” object of the slab layer is a struct kmem_cache, as it represents an instance of a cache.
Creation
#define KMEM_CACHE (struct, flags)// struct is the type of object that wil be stored in the cache// flags are SLAB_POISON, SLAB_RED_ZONE and SLAB_HWCACHE_ALIGN
If your code performs allocations and needs a guarantee that memory will be available, you can use memory pools.
This should be used only if your code will fail if memory is not available.
For example, some drivers performing DMA might need to allocate objects during an operation with hardware, where failure would break the hardware.
A memory pool is a chunk of pre-allocated memory that is guaranteed to be able to store at least a minimal number of objects.
Creation/Destruction
/** * mempool_create - create a memory pool * @min_nr: the minimum number of elements guaranteed to be * allocated for this pool. * @alloc_fn: user-defined element-allocation function. * @free_fn: user-defined element-freeing function. * @pool_data: optional private data available to the user-defined functions. */mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn, mempool_free_t *free_fn,void*pool_data);void mempool_destroy(mempool_t *pool)
If you allocate memory, you need to free it at some point to avoid memory leaks.
There are multiple ways of reclaiming memory for the kernel:
Manually free the memory you allocated when you don’t need it anymore, e.g., with kfree() or kmem_cache_free().
This works well for data that is allocated and freed in a single code path and easy to manage.
Using reference counters to free objects when there are no more references to it.
Works well when objects can be used in different subsystems or by different actors in the kernel.
Memory reclamation by the shrinker under memory pressure.
Should be set up for objects that may take a large portion of memory but are not necessary for your code to work, e.g., you store statistics in memory without limiting the total amount of data you keep, but you are ok with freeing the old data if the system needs memory.
Memory reclamation by the page frame reclamation algorithm (PFRA).
Automatically executed by the kswapd daemon and under heavy memory pressure.
Evicts to storage the least recently used pages.
Reference Counters
Reference counters keep track of the number of users of an object. Whenever the counter reaches 0, the object is not in use anymore and can be freed.
To use a reference counter, you need to embed a struct kref into your structure. It needs to be embedded, not a pointer!
struct wacom_hdev_data {// Example from a Wacom driverstruct list_head list;struct kref kref;struct hid_device *dev;struct wacom_shared shared;};
You can check the full API in include/linux/kref.h, but the main methods are:
/** * kref_get - increment refcount for object. * @kref: object. */void kref_get(struct kref *kref);/** * kref_put - decrement refcount for object. * @kref: object. * @release: pointer to the function that will clean up the object when the * last reference to the object is released. * This pointer is required, and it is not acceptable to pass kfree * in as this function. If the caller does pass kfree to this * function, you will be publicly mocked mercilessly by the kref * maintainer, and anyone else who happens to notice it. You have * been warned. */int kref_put(struct kref *kref,void(*release)(struct kref *kref));
Putting a kref object
The release() function needs to free the object containing the kref.
You can achieve this by using the container_of macro.
Shrinker
If you allocate a lot of objects that are useful but not necessary, you can play nice and let the kernel reclaim your memory if needed.
When the kernel is under memory pressure, it runs the shrinker to reclaim memory from registered components.
To register a shrinker for your code, you first need to declare a struct shrinker and define a count() and a scan() functions.
struct shrinker {unsignedlong(*count_objects)(struct shrinker *,struct shrink_control *sc);unsignedlong(*scan_objects)(struct shrinker *,struct shrink_control *sc);int seeks;/* seeks to recreate an obj */long batch;/* reclaim batch size, 0 = default */unsignedlong flags;/* These are for internal use */struct list_head list;/* objs pending delete, per node */ atomic_long_t *nr_deferred;};
When the kernel wants to reclaim memory, it will call the count() method of all registered shrinkers to assess how many objects can be freed.
It will then call the scan() method if the count is positive in order to actually free the memory.
With your shrinker declared, you still need to register it so that the kernel will call it when memory reclaiming is performed.
You also need to unregister your shrinker when it is not usable anymore, e.g., when you unload your module.
int register_shrinker(struct shrinker *);void unregister_shrinker(struct shrinker *);
Page Frame Reclamation
Linux tries to keep a pool of available free pages to ensure future allocations won’t fail (most likely).
Pages can be of one of four types:
Unreclaimable: Cannot be swapped out and reclaimed, e.g., kernel stacks, locked pages
Swappable: Can be swapped out and reclaimed, e.g., anonymous pages, shared memory
Syncable: Cached disk data that might need to be synced before reclamation if dirty, i.e., page cache
Discardable: Unused pages that can be immediately reclaimed, e.g., unused pages in kernel slab allocators
Page reclamation is performed on two occasions:
During an allocation, when the amount of free pages drops below the low watermark, the kswapd daemon is asynchrounously woken up to reclaim pages
During an allocation, when the amount of free pages drops below the min watermark, a direct reclamation is synchronously performed
Page Frame Reclamation Algorithm (PFRA)
The page frame reclamation algorithm (PFRA) implements a form of Least-Recently Used (LRU) algorithm.
The rationale is the following:
Pages are stored into an LRU list, sorted by access time (this is not really true, we’ll see why later)
When a page is accessed, it is moved to the head of the list
When pages need to be reclaimed, the PFRA starts at the tail of the LRU list
In practice, it is very costly to maintain a sorted LRU list.
Thus, Linux approximates it using a clock algorithm, using the referenced bit from the page table.
There are two versions of the PFRA:
Until 6.0: the two-list strategy
From 6.1: the Multi-Gen LRU (MGLRU)
Let’s have a look at both implementations!
PFRA: Two-List Strategy
The PFRA maintains two lists: the active and the inactive lists.
The active list contains recently accessed pages, while the inactive list contains the pages that were not accessed recently.
In other words, the active list contains the current working set of the system.
When a page is accessed for the first time, it is added in the inactive list, with a referenced bit set to 0.
Periodically, the PFRA scans the lists:
When a page is accessed, its referenced bit is set to 1 by the MMU (used)
If an inactive page’s referenced bit is 1 during the scan, the page is moved to the active list (used)
Periodically (after multiple scans), referenced bits are cleared (timeout)
If an active page’s referenced bit is 0, the page is moved to the inactive list (refill)
If the active list is too long, pages can be moved to the inactive list (refill)
Lengths of lists
The PFRA tries to balance the length of the active and inactive list through a ratio. By default, Linux is usually tuned to have an active list at most two thirds of the page cache’s size.
PFRA: Multi-Gen LRU
Unfortunately, the active/inactive lists have a few shortcomings:
Too coarse-grained: Hard to differentiate the real “age” of a page based on active/inactive status only
Costly: Scanning the lists takes a noticeable amount of time, i.e., kswapd daemon
Biased to evict file-backed pages: Due to the reference counting method, file-backed pages end up evicted much more than idle anonymous pages
In Linux 6.1, the Multi-Gen LRU (MGLRU) was introduced to fix these issues.
It generalises the previous concept with more lists than just active/inactive, called generations.
The general idea and algorithm are the same: pages are moved between generations depending on their use recency. The old algorithm could be described as an MGLRU with two generations.
Having more generations gives a finer-grained estimation of the age of a page:
pages in the same generation have been last accessed roughly at the same period of time.
Each generation is also smaller than with the old version, making the scan faster.
Generations are also now split into tiers that regroup pages that were accessed the same amount of time in the generation.
Other Memory Features in the Kernel
Transparent Huge Pages (THP)
Transparently use huge pages (2 MiB or 1 GiB on x86-64) when allocating large memory areas. Reduces the pressure on the TLB (less entries for the same amount of data) and shortens page table operations (less page table levels to walk though).
Compaction
Reduce fragmentation of the physical memory by compacting pages close to each other. This reduces the amount of holes due to the buddy allocator, and enables merging free buddies, and thus allocating larger memory areas.
Kernel Samepage Merging (KSM)
Deduplication mechanism that can be enabled to detect page frames with the same content and merge them. The resulting page frame is then mapped at each virtual address the original page frames belonged to.
Out-of-Memory Killer (OOM)
When the system critically runs out of memory, the OOM killer chooses a process to sacrifice in order to enough free memory for the system to keep operating without freezing or crashing.
Chapter 6: Virtual File System
The Virtual File System Abstraction
Overview of the VFS
The Virtual File System (VFS) defines a set of abstractions that are then made concrete by file system implementations.
Objects
A file descriptor represents an instance of an open file
An inode represents a file on the storage device
The directory entry caches the resolution of a file path to its corresponding inode
A superblock represents an instance of a mounted file system
Interfaces
File operations operate on file content (open, read, write, …)
Inode operations operate on file metadata (create, mkdir, unlink, …)
Superblock operations operate on a partition (mount, sync, unmount, …)
File Descriptors
File descriptors represent an instance of an open file.
It contains information about the file on storage as well as the current state of the open file, e.g., cursor position.
There can be multiple file descriptors for the same file on storage when opened multiple times.
A file descriptor is defined as a struct file in include/linux/fs.h
struct file { fmode_t f_mode;// mode in which the file is opened (rwxrwxrwx) atomic_long_t f_count;// number of threads sharing this file descriptor loff_t f_pos;// position in the file, the "cursor"struct inode *f_inode;// the inode representing the concrete filestruct file_operations *f_op;struct address_space *f_mapping;// mapping in memory for the page cache/* ... */};
Inodes
Inodes describe files or directories on the storage device.
Each inode corresponds to one and only one file/directory.
Conversely, each file/directory corresponds to one and only one inode.
An inode is defined as a struct inode in include/linux/fs.h
struct inode { umode_t i_mode;// mode of the file on disk kuid_t i_uid;// user id of the owner of the file kgid_t i_gid;// group id of the owner of the fileunsignedlong i_ino;// inode numberunsignedint i_nlink;// number of links to this file (hard links) loff_t i_size;// size of the filestruct timespec64 i_atime;// date of the last accessstruct timespec64 i_mtime;// date of the last modificationstruct timespec64 i_ctime;// date of creationstruct inode_operations *i_op;struct super_block *i_sb;// super block (partition) that contains this inodestruct address_space *i_mapping;// mapping in memory for the page cache};
The inode is partially stored on the disk too, in order to preserve information across mounts/reboots, e.g., file size, timestamps, mode, etc…
Resolving Paths to Inodes
From a user perspective, a file/directory is identified by its path.
The VFS needs to translate this path into an inode to actually interact with the file.
This resolution operation is costly as it requires numerous string operations and walking the directory hierarchy on disk.
To avoid repeating this operation too many times, the VFS builds directory entries, or dentries.
A dentry maintains a relationship between a path and its corresponding inode.
Example: If you open the file located at /home/lkp/foo/bar, it will create/query the following five dentries: /, home, lkp, foo and bar.
Dentries are defined as struct dentry in include/linux/dcache.h
struct dentry {struct qstr d_name;// file namestruct inode *d_inode;// inode of this pathstruct dentry *d_parent;// parent in the fs hierarchystruct super_block *d_sb;// mounted file system owning this dentrystruct hlist_bl_node d_hash;// list for the hash table};
Dentries can be in one of three states:
Used:dentry points to a valid inode (d_inode points to an inode) and is in the dentry cache
Unused:dentry is allocated but not in use currently, kept in cache for future reuse
Negative:dentry does not point to a valid inode (d_inode is NULL) (you will see why this is useful for in the lab)
Dentry Cache
Dentries are cached into a hash table for fast lookup.
This cache is declared as staticstruct hlist_bl_head *dentry_hashtable in fs/dcache.c.
Spoiler alert!
No more details here, you will have to work with that cache in the next lab.
In particular, you will have to find out:
the dentry cache size (number of buckets)
how the hash table is implemented
what are negative dentries used for
Back to the VFS
Now, let’s go back to our layers, and more specifically how the VFS glues all this together
Relations Between VFS Objects
File System
As shown in the previous figure, implementing a file system means implementing a set of file and inode operations.
File systems may also add their own flavor of inode definition.
Example: The ext4 file system has this inode definition that extends the VFS inode:
struct ext4_inode { __le16 i_mode;/* File mode */ __le16 i_uid;/* Low 16 bits of Owner Uid */ __le32 i_size_lo;/* Size in bytes */ __le32 i_atime;/* Access time */ __le32 i_ctime;/* Inode Change time */ __le32 i_mtime;/* Modification time */ __le32 i_dtime;/* Deletion Time */ __le16 i_gid;/* Low 16 bits of Group Id */ __le16 i_links_count;/* Links count */ __le32 i_blocks_lo;/* Blocks count */ __le32 i_flags;/* File flags */ __le16 i_checksum_hi;/* crc32c(uuid+inum+inode) BE */ __le32 i_generation;/* File version (for NFS) */ __le32 i_file_acl_lo;/* File ACL */};
Accessing storage device is two orders of magnitude longer than accessing memory!
To alleviate this, Linux has a page cache sitting between file systems and storage devices.
Pages read from block devices are cached in memory for fast access
The page cache employs a write-back policy: writes are asynchronously propagated to the storage device
The page cache does not have a size, it uses all the free memory available. When free memory is needed, the PFRA evicts pages
Relations Between VFS Objects and the Page Cache
The xarray in the address_space may contain folios instead of pages depending on the file system. We won’t go into more details on this, but if you want to have a look, you can check the kernel documentation/online resources.
Super Block
A super block describes a mounted file system partition. On mount, a struct super_block is created and populated with data read from storage.
This structure is defined in include/linux/fs.h:
struct super_block {struct block_device *s_bdev;// the block device containing this partitionunsignedlong s_blocksize;// size of a block loff_t s_maxbytes;// max file sizestruct file_system_type *s_type;// file system descriptorstruct super_operations *s_op;// fs ops (alloc_inode, sync, umount)struct dentry *s_root;// dentry of the root of the mount point (the / of this partition)unsignedlong s_magic;// magic number of this file systemvoid*s_fs_info;// file system-specific private infochar s_id[32];// short name uuid_t s_uuid;// UUID/* ... */};
The operations on super blocks are also defined in include/linux/fs.h:
Relations Between VFS Objects (Super Block Edition)
Implementing a File System
To implement a file system, you need to:
Design the layout on your physical storage device
Design your super block and how inodes and blocks are managed
Design your inode content (what information must be stored)
Design the operations on your file system
File operations (open, read, write, …)
Inode operations (create, unlink, mkdir, …)
Super block operations (alloc_inode, sync, …)
Page cache operations if you want to use it
For 1., this mostly means implementing the mkfs user space utility for your new file system.
For 2., this is your kernel implementation as a module.
File system in User SpacE
Another way of implementing a file system in Linux is through the File system in User SpacE (FUSE) API.
With FUSE, you can implement everything in user space and register your FUSE file system with the kernel.
The VFS will then redirect system calls targeting your file system to your code in user space, which in turn may use the underlying “real” file system.
Performance
The amount of round trips between user and kernel modes greatly impacts the performance of FUSE-based file systems.
FUSE Passthrough
Since 6.9, the FUSE subsystem supports a passthrough feature to avoid mode switches.
It allows the FUSE driver to directly communicate with other file systems for read/write operations, without going back to the user space FUSE daemon.
Project Teaser Trailer
Spoiler Alert!!!
What we have seen today will be useful for the project!
You will need to…implement new features in a simple file system provided to you: ouichefs!
The list of features to implement is a surprise. We will announce it in two weeks.
The system call ptrace allows a thread (the tracer) to observe and control the execution of another thread (the tracee).
long ptrace(enum __ptrace_request request, pid_t pid,void*addr,void*data);
The tracer sends commands (requests) to observe or modify the behavior of the tracee, and the tracee is stopped on events specified by the tracer.
Some commands:
PTRACE_ATTACH/PTRACE_SEIZE: trace the specified thread.
PTRACE_TRACEME: used by a tracee to ask its parent to trace it.
PTRACE_GETREGS/PTRACE_SETREGS: get/set the registers of the tracee.
PTRACE_GETSIGINFO/PTRACE_SETSIGINFO: get/set the information about the signal that caused the tracee to stop.
PTRACE_CONT: make a stopped tracee resume its execution.
PTRACE_SYSCALL: same as PTRACE_CONT, but also makes the tracee stop at the next syscall entry/exit.
PTRACE_SINGLESTEP: same as PTRACE_CONT, but also makes the tracee stop after executing one instruction.
Ftrace – Function tracer
Ftrace is a kernel facility to monitor the behavior of the kernel.
Unlike its name suggests, it is not only a function tracer.
It provides the following features:
Function tracer:
When/how many times a function is called
Function execution time
Function call graph
Latency tracer:
Interrupt handling latency
Interrupts disabled latency
Task wake up latency
OS noise
Function prober:
Hook code at the entry/exit of any function of the kernel
Useful for tracing, monitoring, patching
Ftrace – User perspective
Ftrace exposes a pseudo file system to user space, mounted in /sys/kernel/tracing/ (and also in /sys/kernel/debug/tracing/ for backward compatibility). If it is not, you can mount it with:
$ mount -t tracefs nodev /sys/kernel/tracing
It exposes files and directories to control the tracers, set filters, read the trace, etc.
# tracer: function_graph## CPU DURATION FUNCTION CALLS# | | | | | | |------------------------------------------14)QuotaMa-56957 => cat-519885 ------------------------------------------14)|__x64_sys_read(){14)|ksys_read(){14)|__fdget_pos(){14)0.563 us |__fget_light();14)1.705 us |}14)|vfs_read(){14)|rw_verify_area(){14)|security_file_permission(){14)0.422 us |bpf_lsm_file_permission();14)0.488 us |__fsnotify_parent();14)2.216 us |}14)3.035 us |}14)0.601 us |__get_task_ioprio();14)|ext4_file_read_iter[ext4](){14)|generic_file_read_iter(){14)|filemap_read(){14)|filemap_get_pages(){14)|filemap_get_read_batch(){14)0.424 us |__rcu_read_lock();14)0.440 us |__rcu_read_unlock();14)2.537 us |}14)3.419 us |}14)0.430 us |folio_mark_accessed();14)|touch_atime(){14)|atime_needs_update(){14)0.476 us |make_vfsuid();14)0.423 us |make_vfsgid();14)|current_time(){14)0.480 us |ktime_get_coarse_real_ts64();14)1.312 us |}14)3.838 us |}14)4.625 us |}14)+ 11.279 us |}14)+ 12.038 us |}14)+ 12.860 us |}14)0.492 us |__fsnotify_parent();14)+ 19.284 us |}14)+ 22.507 us |}14)+ 25.423 us |}
Ftrace – User front ends
In practice, you most likely will use a front-end tool instead of directly configuring ftrace.
You can use the callback patching mechanism to call your own functions before/after any function in the kernel. This mechanism is called fprobe1.
This can be used to add measurements, filtering function parameters, etc.
The callbacks need to be in kernel space, so they should be part of a module or in the kernel binary.
To define a new probe, you must define a struct fprobe:
/* `filter` and `notfilter` are wildcard patterns to match symbol names to probe or not, respectively. */int register_fprobe(struct fprobe *fp,constchar*filter,constchar*notfilter);int unregister_fprobe(struct fprobe *fp);/* Example: fp handlers will be called for functions names matching "func*()" (e.g. func0(), func1()) but not "func2()" */register_fprobe(&fp,"func*","func2");
You can also temporarily enable/disable registered probes with:
Kernel developers can also add predefined events that can be dynamically traced: tracepoints1.
These events are directly in the kernel code as function calls, e.g., when a kthread stops:
int kthread_stop(struct task_struct *k){/* some code */ trace_sched_kthread_stop(k);/* some code */}
They are defined through macros in header files 2:
TRACE_EVENT(sched_kthread_stop,// event name, the tracepoint will be called trace_<name>() TP_PROTO(struct task_struct *t),// prototype of the function TP_ARGS(t),// names of the argument (same as in TP_PROTO, needed to avoid ugly macros) TP_STRUCT__entry(// "local variable" called `__entry` that defines the layout of the data logged in this event __array(char, comm, TASK_COMM_LEN )// equivalent to `char comm[TASK_COMM_LEN];` __field( pid_t, pid )// equivalent to `pid_t pid;`), TP_fast_assign(// C statements to initialize the `__entry` variable memcpy(__entry->comm, t->comm, TASK_COMM_LEN); __entry->pid = t->pid;), TP_printk("comm=%s pid=%d", __entry->comm, __entry->pid)// formatted output of the event as exposed to user space);
eBPF (extended Berkeley Packet Filter) is a managed runtime environment embedded in the kernel.
It defines an instruction set (bytecode), data structures (maps), primitives, as well as a run time infrastructure to execute eBPF programs.
eBPF – Writing eBPF programs
There are multiple ways of writing eBPF programs:
Directly write eBPF bytecode Cumbersome, don’t do that
bcc (BPF Compiler Collection)
Toolkit to generate eBPF programs for the kernel in C, with Python and lua front-ends.
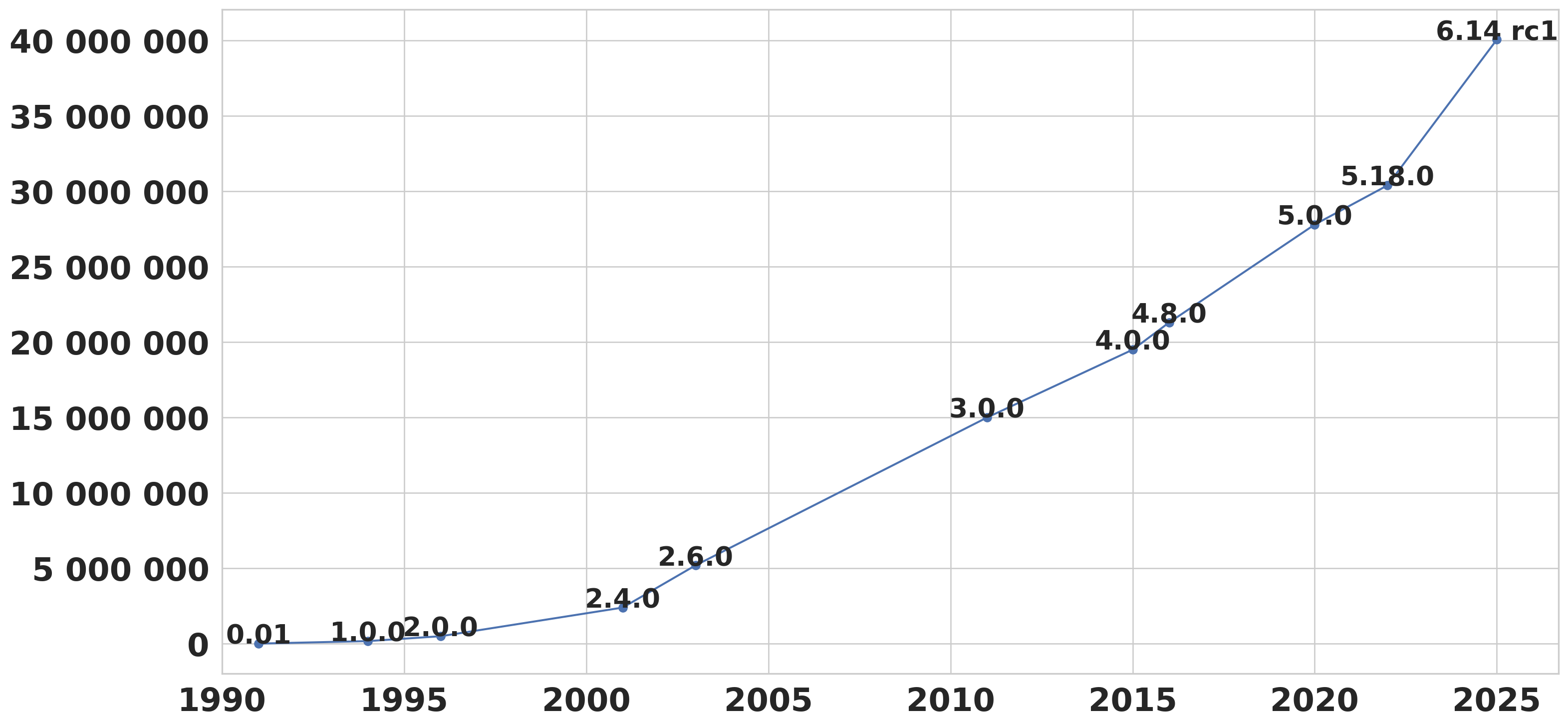








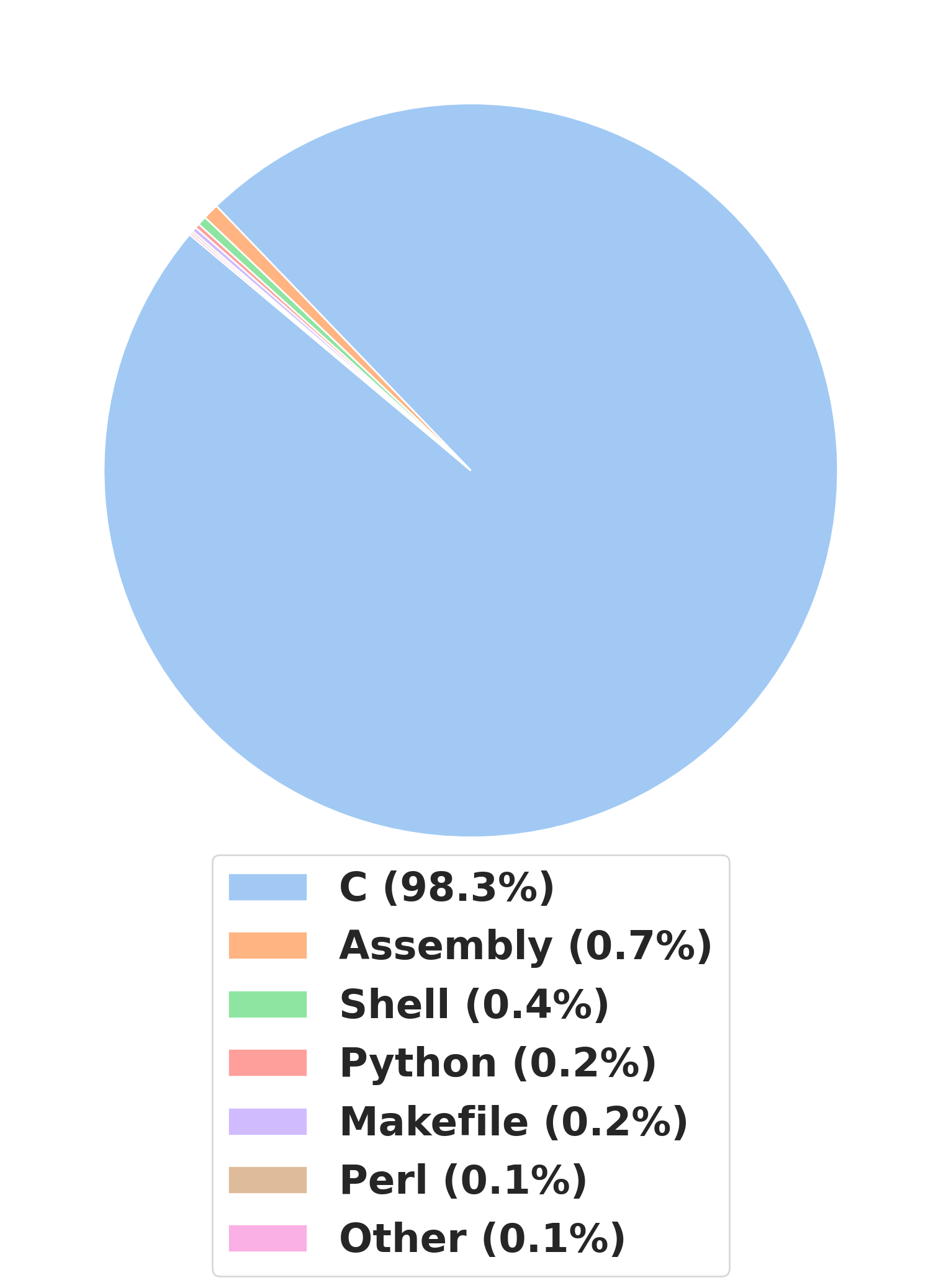






























































































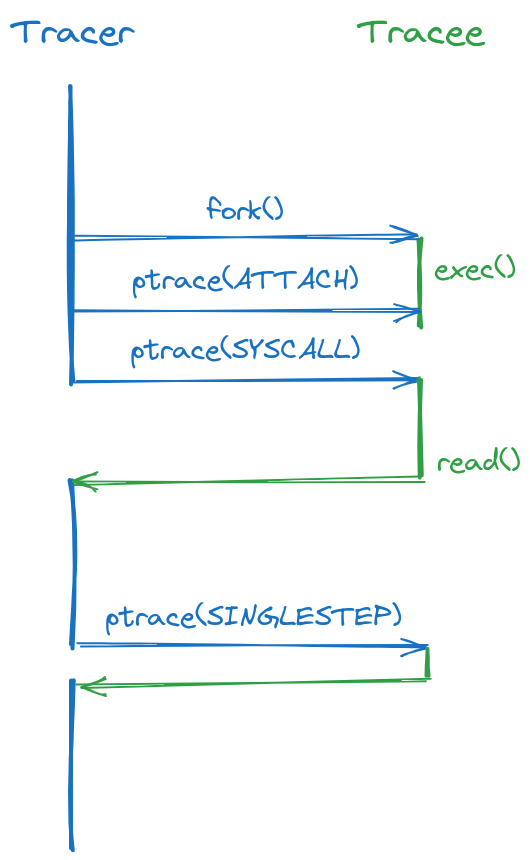


{kind=link}
{kind=link}