Exercises: 1x week
Present solutions to the previous week’s assignments
Tutorials: 1x week, 23 groups (EN, DE or both)
Solve and discuss assignments in small groups
Topics:
Introduction to operating systems
Processes and threads / Scheduling
Memory management
File management
I/O devices and interrupts
Concurrency and Synchronization
User space OS (System calls, shared libraries)
Virtualization and containers
Week Planning
Day
Time
Where
Room
Lectures
Tuesday
16:30 – 18:00
1385 C.A.R.L.
H01
Thursday
14:30 – 16:00
1385 C.A.R.L.
H01
Exercise
Monday
10:30 – 12:00
1515 TEMP
001
Tutorial groups
Check slots and register on RWTHonline!
Weekly Programming Assignments
Every week, you get programming assignments:
On Moodle, with the VPL platform
Automatically graded
Individual submission, but you are allowed to help each other in small groups (without copying solutions)
Planning:
For a given topic \(T_i\), e.g., memory management:
The tutorials covering \(T_i\) will happen on week \(i\)
After the last tutorial on week \(i\), the graded assignment will be released (Friday at around 14:00)
You have until the Global Exercise (Monday 10:30) on week \(T_{i+2}\) to complete the assignment.
This gives you roughly 10 days to complete the assignment.
The assignment solution will be provided and discussed in the Global Exercise just after the deadline (Monday 10:30), on week \(T_{i+2}\)
The VPL platform will run tests on a Linux system.
If you want to work locally on your own machine (and not directly on Moodle), we strongly recommend using Linux.
You can also use Windows with the Windows Subsystem for Linux (WSL) or MacOS.
C/Shell Programming
The assignments will be done in the C programming language, and you are expected to have basic programming skills in C and shell scripting for the lectures and exams.
You can find many resources online to learn C and shell scripting, including tutorials, courses and books.
This is a first year course, which means that the labs are designed to be doable by students with basic programming skills.
That also means that you can find help and solutions online, including on large language models (LLMs).
We cannot and will not monitor the use of LLMs, but we expect you to use them responsibly and ethically.
Recommended usage:
Use them to get hints and explanations about concepts you don’t understand, but try to solve the assignments on your own first.
If you get stuck, you can ask for help, but try to understand the solution and not just copy-paste it.
This is for your own benefit, as using LLMs to solve the assignments without understanding the solutions will not help you in the long run, especially for the written exam.
Tip
Don’t hesitate to also use other sources, e.g., Stack Overflow. LLMs are not the alpha and omega, and they can be wrong, even when they sound very sure of themselves, or give you solutions that are not adapted to the specific requirements of the assignment.
Course Evaluation
The evaluation of this course is split into two parts that participate in your final score out of 100%:
Weekly assignments
Programming assignments on VPL every week.
At the end of the semester, a special bonus assignment will be released.
Weight: 20% of the final score + 10% bonus points for the exam
Written exam
Mostly concept questions and exercises. You won’t have to write code from scratch.
At most, we may give you some code to read and explain/fix, or have you write a couple of lines.
Weight: 80% of the final score
The sum of both parts will give you your final score, which is then used to calculate your final grade as follows:
Score
Grade
95 - 100
1,0
90 - 94
1,3
85 - 89
1,7
80 - 84
2,0
Score
Grade
75 - 79
2,3
70 - 74
2,7
65 - 69
3,0
60 - 64
3,3
Score
Grade
55 - 59
3,7
50 - 54
4,0
00 - 49
5,0
You need to get a passing grade (at least half of the total points) in each part to pass the course!
These slides are synchronized with the lecture, i.e., pages will change at the same time as the live presentation.
Live Q&A
During lectures, you can ask questions anonymously using our locally hosted Claper instance
This room is open only during lectures!
Course Color Codes
We will try to use the following color codes in our slides to help you identify the type of content:
Note, summary
Solution, answer, idea
Warning, error, common mistake
Info, tip, best practice
Definition
References
Books
Modern Operating Systems, Fifth Edition Andrew S. Tanenbaum, Herbert Bos (2023)
The Design and Implementation of the FreeBSD Operating System, Second Edition Marshall K. McKusick, George V. Neville-Neil, Robert N.M. Watson (2015)
The C Programming Language, Second Edition Brian W. Kernighan, Dennis M. Ritchie (1988)
Linux Kernel Development, Third Edition Robert Love (2010)
Chapter 1: Introduction to Operating Systems
This Week’s Program
In this first week, we’ll start slow, first defining what an operating system is, its general architecture, and how it is used by applications.
Overview of Operating Systems Definitions and general concepts, history
Protection Domains and Processor Privilege Levels Software and hardware isolation mechanisms between the OS and user applications
Operating System Architectures Main OS architectures and designs, their pros and cons
Overview of Operating Systems
What Is an Operating System?
Computer systems are complex machines with a large number of components:
Internal chips: processor(s), memory
Storage devices: hard drives (HDD), solid state drives (SSD), etc.
PCI devices: network cards, graphics cards, etc.
Peripherals: keyboard, mouse, display, etc.
Application programmers cannot be expected to know how to program all these devices.
And even if they do, they would rewrite the exact same code for every application, e.g., the code to read inputs from the keyboard.
Resources can be shared by multiple programs.
Expecting programs to collaborate and not mess with each other is not possible, e.g., two programs try to print at the same time, but the printer can only print one coherent job at a time.
The operating system is the software layer that lies between applications and hardware.
It provides applications a simpler interface with hardware and manages resources.
What Is an Operating System? (2)
The operating system is the glue between hardware and user applications.
It can be split into two parts:
User interface programs: libraries, shell, graphical interfaces (GUI), etc.
They offer a high level of abstractions, and are usually used by user applications to manipulate the underlying system.
Kernel: executes critical operations with a high level of privilege (supervisor mode) and directly interacts with hardware.
User interface programs go through the kernel to manipulate the state of the underlying hardware.
In this course, we will mostly focus on the kernel part of the operating system.
What Is the Operating System’s Job?
The operating system has two main jobs:
From the applications’ perspective: provide easy abstractions to use the hardware
From the hardware’s perspective: manage the resources for controlled and safe use
Abstraction layer
Hardware is complex and provides messy interfaces. Devices may have their own design and interfaces, even when they have the same goal, e.g., hard drives may respond to different types of commands for the same functional task.
Resource manager
Hardware resources are shared by multiple programs and need to be properly managed to allow safe use, e.g., if two programs try to use the same hard drive, we need to make sure they are not unsafely modifying the same data.
The operating system must provide a simple and clean interface to access hardware resources.
The operating system must provide a safe and controlled allocation of resources to programs.
Main Operating System Services
Most operating systems are expected to provide the following features to user applications:
Program management execution environment, synchronization, scheduling, etc.
Memory management memory allocation, isolation
File management file system, standardized API, cache, etc.
Network management network topology, protocols, APIs, etc.
Human interface IO peripherals, display, etc.
A Brief History of Computers and Operating Systems
First mechanical computers
Charles Babbage’s Analytical engine (1837)
Turing complete. Programs on punch cards. Never fully built, a simplified version was built by his son later.
First program written by Ada Lovelace (computing Bernoulli numbers).
Calculating machine of Babbage’s Analytical Engine. Source: Wikimedia
No real operating systems, operators reserved the machines, programmed them or manually inserted the punch cards, and waited for the results.
A Brief History of Computers and Operating Systems (3)
Second generation: Transistor computers (1955 – 1965)
With transistors, computers become reliable enough for commercial use. Mainframes are bought by corporations, government agencies and universities, e.g., weather forecast, engineering simulation, accounting, etc.
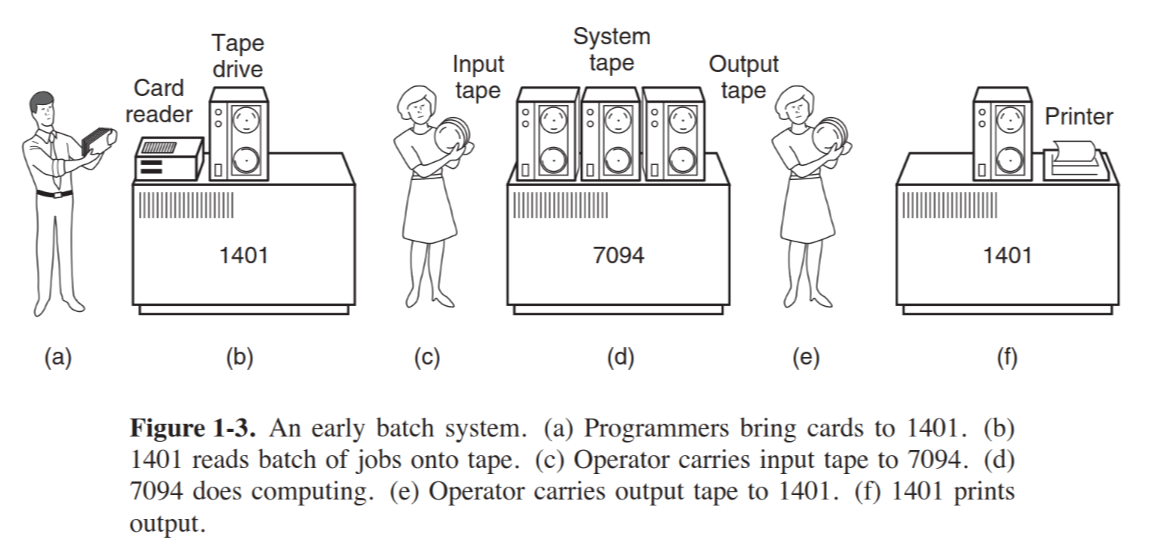
First real of operating systems with GM-NAA I/O (1956), IBSYS (1960), working in batch mode to schedule and pipeline jobs.
Source: Modern Operating Systems, A. S. Tanenbaum, H. Bos, page 9.
Time sharing systems with CTSS (1961) and BBN Time-Sharing System (1962).
First minicomputers for individual users: PDP-1 (1961), LINC (1962).
NASA computer room with two IBM 7090s, 1962. Source: Wikimedia
A Brief History of Computers and Operating Systems (4)
Third generation: Integrated circuits (1965 – 1980)
Minicomputers and mainframes are becoming more commonplace.
IBM releases its OS/360 (1966) that features multiprogramming.
MIT, Bell and General Electric develop Multics (1969) that pioneered a lot of common OS concepts e.g., hierarchical file systems, protection domains, dynamic linking, processes.
Bell (Ken Thompson, Dennis Ritchie, et al.) develop UNIX (1969-71) influenced by Multics, with novel concepts e.g., “everything is a file” philosophy, inter-process communication (pipes), unified file systems.
This later on led to the creation of the POSIX standard.
UNIX will influence the design of many operating systems:
Berkeley’s BSD (1978)
AT&T’s System V (1983)
Vrije University’s MINIX (1987)
Linux (1991)
A Brief History of Computers and Operating Systems (5)
Third generation: Personal computers (1980 – today)
Large scale integration enabled to build chips with thousands of transistors/mm2 (hundreds of millions today).
Thus, microcomputers for personal use became powerful and affordable.
1974: Intel releases the 8080, the first 8-bit general purpose CPU and the first disk-based OS: CP/M.
1980: IBM designs the IBM PC and tasks Bill Gates (Microsoft) to find them a suitable OS.
He purchases DOS (Disk Operating System) from a Seattle-based company and licenses it to IBM for the PC.
1981: IBM releases the PC with MS-DOS as its operating system.
1984: Apple releases the Macintosh with MacOS featuring a graphical user interface (GUI). the first GUI was developed at Xerox, but they did not realize its potential, unlike Steve Jobs…
Fast forward to today:
Microsoft develops Windows
on top of MS-DOS: Windows 1.0 to 3.1, Windows 95, 98, ME
with the Windows NT family: NT, 2000, XP, Vista, 7, 8, 10, 11
Apple continues to develop macOS
Mac OS versions 1 to 9 (2001)
Mac OS X (and now macOS) with a new hybrid kernel (2001 – today)
iOS, iPadOS, watchOS
Linux is everywhere on the server market and embedded devices, e.g., Android
A Quick Review of Computing Hardware
Overview
A computer system is a set of chips, devices and communication hardware.
It comprises:
Computing hardware that executes programs Central Processing Unit (CPU)
Memory to store volatile information with fast access Random Access Memory (RAM), caches
Various device controllers to communicate with hardware devices using different specifications Disk, video, USB, network, etc.
A communication layer that enables all these components to communicate commands and data Bus, interconnect, PCIe, etc.
Central Processing Unit
The Central Processing Unit, or CPU/processor, is the brain of the computer.
Its job is to load an instruction from memory, decode and execute it, and then move on to the next instruction and repeat.
Each CPU understands one “language”, its instruction set, e.g., x86, ARMv7, which makes them not interoperable.
A CPU contains the following components:
Execution units that execute instructions
Decoder reads an instruction and forwards to the proper execution unit
Arithmetic/Logical Unit (ALU) performs integer and binary operations
Floating-Point Unit (FPU) performs floating-point operations
Memory Unit (MU) performs memory accesses
Registers that store data
State information, e.g., instruction pointer, stack pointer, return address
Program values in general-purpose registers
Multiple levels of caches to avoid performing redundant and costly memory accesses
Memory and Devices
The CPU is the “brain” of the computer and acts “by itself”(following the running program instructions).
The other components act as they are instructed by the CPU.
Memory is a passive device that stores data. The CPU and devices read from and write to it.
Other devices perform operations as instructed by the CPU. e.g., display something on the monitor, send this through the network, etc.
Communication between components happens through the bus, the communication layer that links them.
Protection Domains and Processor Privilege Levels
The Need for Isolation
Some operations are critical and could break the system if done improperly:
Modify the state of a device e.g., modify the state of the microphone LED to make it look muted when it is not e.g., make a USB drive read-only/writable
Access restricted memory areas e.g., modify a variable from another program e.g., read private data – passwords – from other programs
We cannot trust all application software to not do these critical operations!
User applications can be written by anyone:
Programmers lacking skills/experience/knowledge
Malicious programmers that want to attack a system
The operating system needs to isolate these operations to make the system safe and secure!
Protection Domains
In order to provide the necessary isolation, operating systems provide different protection domains or modes.
These domains give different capabilities to the code executing on the machine.
Usually, two protection domains are provided:
Supervisor mode
User mode
They have different privilege levels, allowing or restricting a set of operations.
Protection domains are software-defined by the operating system.
The OS relies on hardware features to be enforce them. (We will discuss these features later on.)
Supervisor Domain
Supervisor domain (also referred to as S mode) has the highest privilege level.
This means that all operations are allowed.
Programs running in this domain can:
Use all the instruction set defined by the CPU architecture
Directly interact with hardware devices
Access any memory area
This domain is used by the kernel that contains the low level components of the operating system.
User Domain
User domain (also referred to as U mode) has the lowest privilege level.
This means that some operations are restricted in this domain.
Programs running in this domain cannot:
Use privileged instructions that modify the system state, e.g., directly manipulate a hardware device
Access some memory areas, e.g., access the memory of another program
This domain is used by all the applications outside of the kernel: high level operating system services and user applications.
Relationship Between Protection Domains
User mode is usually a subset of supervisor mode.
All the operations that can be performed in user mode can also be performed in supervisor mode.
Protection domains are usually enforced with features provided by the hardware.
Processor Privilege Levels
In practice, protection domains are backed by hardware processor privilege levels, also called CPU modes or CPU states.
For example, x86 provides four levels, also called protection rings.
ARMv7 provides three privilege levels, while ARMv8 provides four.
x86 protection rings
ARMv7 privilege levels
Careful with the numbers!
There is no standard order in the value of the levels! For x86, ring 0 is the most privileged, while PL0 is the least privileged on ARMv7!
Matching Protection Domains to Privilege Levels
Most operating systems use two protection domains (user and supervisor), e.g., Linux, Windows, macOS.
Thus, they only need two processor privilege levels, as specified by the Instruction Set Architecture:
Protection domains and protection rings on x86 platforms
Protection domains and privilege levels on ARMv7 platforms
Virtualized context
In virtualized environments, the hypervisor needs specific instructions.
On x86, they are in a new ring -1 level, while ARMv7 uses its PL2 level.
Switching Between Modes
When applications running in user mode need to use a privileged feature, they have to switch to supervisor mode e.g., writing to a file on disk, allocating memory, etc.
This switching is performed through system calls, which are function calls from user to supervisor mode.
They provide a controlled interface between user space applications and privileged operating system services.
This ensures that user applications can perform privileged operations in a secure way, only through kernel code.
Examples:read() and write() for file manipulation, listen(), send() and receive() for networking
In addition to calling the function, a system call also checks that:
The program is allowed to perform this request e.g., the program is not trying to manipulate a resource it is not allowed to access
The arguments passed by the program are valid e.g., the program is not trying to get privileged information with a forged pointer
Important
During a system call, the user program switches to supervisor mode to execute privileged code!
The user program does not “ask the kernel” to do something!
Protection Domains and Operating System Architecture
Let’s go back to our operating system architecture and add the protection domains.
User applications and high level operating system services run in user mode.
The kernel runs in supervisor mode.
Which components of the operating system are in the kernel?
Operating System Architectures
Supervisor or User Mode? That Is the Question
When designing an operating system, one main question has to be answered:
Which component will run in supervisor mode (and which in user mode)?
In other words:
Which components of the operating system are part of the kernel?
Some components have to be in the kernel because they need privileged instructions.
Other components can reside anywhere. Their position will have an impact on safety, performance and API.
There are four main architectures:
Monolithic kernels
Microkernels
Hybrid kernels
Unikernels
Let’s have a look at these different architectures!
Monolithic Kernels
A monolithic kernel provides, in kernel space, a large amount of core features, e.g., process and memory management, synchronization, file systems, etc., as well as device drivers.
Characteristics
Defines a high level interface through system calls
Good performance when kernel components communicate (regular function calls in kernel space)
Limited safety: if one kernel component crashes, the whole system crashes
Examples
Unix family: BSD, Solaris
Unix-like: Linux
DOS: MS-DOS
Critical embedded systems: Cisco IOS
Modularity
Monolithic kernels can be modular and allow dynamic loading of code, e.g., drivers. These are sometimes called modular monolithic kernels.
A microkernel contains only the minimal set of features needed in kernel space: address-space management, basic scheduling and basic inter-process communication. All other services are pushed in user space as servers: file systems, device drivers, high level interfaces, etc.
Characteristics
Small memory footprint, making it a good choice for embedded systems
Enhanced safety: when a user space server crashes, it does not crash the whole system
Adaptability: servers can be replaced/updated easily, without rebooting
Limited performance: IPCs are costly and numerous in such an architecture
The hybrid kernel architecture sits between monolithic kernels and microkernels.
It is a monolithic kernel where some components have been moved out of kernel space as servers running in user space.
While the structure is similar microkernels, i.e., using user servers, hybrid kernels do not provide the same safety guarantees as most components still run in the kernel.
This architecture’s existence is controversial, as some just define it as a stripped down monolithic kernel.
A unikernel, or library operating system, embeds all the software in supervisor mode.
The kernel as well as all user applications run in the same privileged mode.
It is used to build single application operating systems, embedding only the necessary set of applications in a minimal image.
Characteristics
High peformance: system calls become regular function calls and no copies between user and kernel spaces
Security: attack surface is minimized, easier to harden
Usability: hard to build unikernels due to lack of features supported
Examples
Unikraft
clickOS
IncludeOS
Comparison Between Kernel Architectures
The choice of architecture has various impacts on performance, safety and interfaces:
Switching modes is costly: minimizing mode switches improves performance
Supervisor mode is not safe: minimizing code in supervisor mode improves safety and reliability
High level interfaces for programmers are in different locations depending on the architecture i.e., in the kernel for monolithic, but in libraries or servers for microkernels
Recap
Recap
Definition
The operating system is the software layer that lies between applications and hardware.
It provides applications simple abstractions to interact with hardware and manages resources.
It usually offers the following services: program management, memory management, storage management, networking and human interface.
Protection domains Supervisor mode for critical operations in the kernel, user mode for the non-critical OS services and user applications.
Hardware enforces these with processor privilege levels. System calls allow user mode applications to use supervisor mode services.
They are independent entities that the OS manipulates, choosing which one to run and when.
Caution
Program \(\neq\) process! The program is the ‘recipe’ (the code) and the process is an execution of the program.
Process Creation
A new process can be created for various reasons:
A user creates it by starting a new program e.g., by clicking on the icon or starting it from the command line
Another process creates it using a process creation system call e.g., your web browser starts your PDF reader after downloading a file
When the system starts an initial process is created to initialize the system, launch other programs like the desktop environment, etc.
Depending on their purpose, processes can be classified as:
Foreground processes that interact with the user e.g., video player, calculator, etc.
Background processes that run by themselves with no user interaction required e.g., weather service, notification service, network configuration, etc.
Note
Background processes that always stay in the background are also called daemons or services.
Process Hierarchy
Most systems keep an association between a process and the process that created it, its parent.
In UNIX-based systems, all processes are linked in this way, creating a process tree,
The root of the tree is init, the first process created when the system boots.
The init process also adopts orphaned processes. e.g., if gnome-terminal terminates without terminating
its child processes (ssh and emacs), they become children of init
Windows does not keep a full process tree.
Parent processes are given a handle on their children.
The handle can be passed on to another process.
Process States
After its creation, a process can go into three different states:
Ready(also called runnable)
The process can be executed and is waiting for the scheduler to allocate a CPU for it
Running
The process is currently being executed on the CPU
Blocked
The process cannot run because it is waiting for an event to complete
State transitions:
Process creation ( \(\emptyset \rightarrow\)ready)
Scheduler picks the process to run on the CPU (ready\(\rightarrow\)running)
Scheduler picks another process to run on the CPU (running\(\rightarrow\)ready)
Process cannot continue to run, waiting for an event (running\(\rightarrow\)blocked) e.g., keyboard input, network packet, etc.
Blocking event is complete, the process is ready to run again (blocked\(\rightarrow\)ready)
Process Execution Patterns and Scheduling
Processes have different behaviors depending on the program they execute.
A command line interpreter (CLI) repeatedly:
Waits for a user to type in commands (running\(\rightarrow\)blocked)
Wakes up and executes them when available (blocked\(\rightarrow\)ready\(\leftrightarrow\)running)
A video player repeatedly:
Reads data from disk and waits for it to be available in memory (running\(\rightarrow\)blocked)
Copies the frames into graphical memory (blocked\(\rightarrow\)ready\(\leftrightarrow\)running)
A program that computes digits of \(\pi\) never waits and only uses the CPU (ready\(\leftrightarrow\)running)
Definition
The scheduler is the component of the OS that manages the allocation of CPU resources to processes, depending on their state.
Process Implementation
For each process, the OS maintains a process control block (PCB) to describe it.
Process Memory Layout
A process’ memory, or address space, is split into several sections.
Kernel memory is shared between all processes, accessible only in supervisor mode In 32 bit Linux, 1 GB for the kernel, 3 GB for user space. In 64 bit Linux, 128 TB for the kernel, 128 TB for user space
Text is where the program binary is loaded in memory It contains the actual binary instructions that will be executed by the CPU.
Data contains the static initialized variables from the binary Initialized global variables and static local variables, constant strings e.g., a global\(~~~~\)int count =0;\(~~~~\)or a local\(~~~~\)staticint idx =0;
Stack contains local variables, environment variable, calling context (stack frame) Grows towards address 0x00000000
Process Registers
Registers are the part of the process state that are physically on the CPU
Instruction Pointer (IP), or Program Counter (PC)
Contains the address of the next instruction to execute if not jumping x86-64: RIP arm64: PC
Stack Pointer (SP)
Contains the address of the top of the stack x86-64: RSP arm64: SP
General Purpose (GP)
Contains values or addresses used by instructions x86-64: RAX, RBX, …, R15 arm64: X0–X30
Page Table Pointer
Contains the address of the memory mapping x86-64: CR3 arm64: TTBR
We’ll come back to how memory mappings and page tables work in a future lecture.
Context Switch
When the OS changes the currently running process, it performs a context switch.
The OS needs to exchange the PCB of the current process with the PCB of the next process.
Context switching between the running process A and the ready process B happens in several steps:
Change the state of the currently running process A to ready
Save the CPU registers into A’s PCB
Copy the registers from B’s PCB into the CPU registers
Change the state of B from ready to running
Process Isolation
Another property of processes is that they are isolated from each other.
They act independently, as if they were running alone on the machine.
They do not share memory, open files, etc.
We will see how this is enforced later when discussing memory and file management.
Multiprocessing
Processes can communicate and collaborate if explicitly stated in the program.
We will discuss that in a future lecture.
POSIX API: Processes
Let’s quickly see the POSIX API to manage processes in C.
pid_t fork(void);
Create a new process by duplicating the calling process, i.e., its PCB and memory.
Upon success, returns the PID of the child in the parent, 0 in the child. Returns -1 upon error.
int exec[lvpe](constchar*path,constchar*arg,...);
This family of functions replaces the current program with the one passed as a parameter.
Returns -1 upon error. Upon success, it doesn’t return, but the new program starts.
pid_t wait(int*status);
Wait for any child process to terminate or have a change of state due to a signal.
Returns the PID of the child on success, -1 on failure.
POSIX API: Processes – Example
fork.c
#include <stdio.h>#include <stdlib.h>#include <unistd.h>#include <sys/wait.h>int main(int argc,char**argv){ pid_t pid; printf("Parent PID: %d\n", getpid()); pid = fork();switch(pid){case-1: printf("[%d] Fork failed...\n", getpid());return EXIT_FAILURE;case0: printf("[%d] I am the child!\n", getpid()); sleep(3); printf("[%d] I waited 3 seconds\n", getpid());break;default: printf("[%d] Fork success, my child is PID %d\n", getpid(), pid); wait(NULL); printf("[%d] Child has terminated, wait is over\n", getpid());}return EXIT_SUCCESS;}
❱ gcc -o fork fork.c
❱ ./fork
Parent PID: 254
[254] Fork success, my child has PID 255
[255] I am the child!
[255] I waited 3 seconds
[254] Child has terminated, wait over
Processes: A Heavyweight Mechanism
Applications may benefit from executing multiple tasks at the same time, e.g., your development environment needs to wait for keyboard input, perform syntax check, render the UI, run extensions, etc.
Using one process per task is not always a good idea!
Creating a process means copying an existing one
\(\rightarrow\)
It is a costly operation!
Processes don’t share memory
\(\rightarrow\)
\(\rightarrow\)
Good for isolation.
Communication channels must be explicitly set up!
Is there a more lightweight mechanism to execute parallel programs?
Threads
Definition
A thread is the entity that executes instructions. It has a program counter, registers and a stack.
A process contains one or more threads, and threads in the same process share their memory.
Threads are sometimes called lightweight processes.
Info
Another definition of a process is a set of threads sharing an address space.
But we will discuss that definition in future lectures when explaining memory management and virtual memory.
Process Model and Thread Model
Let’s go back to our process model, and add threads in the mix.
Processes group resources together, e.g., memory, open files, signals, etc., while threads execute code.
Example 1: Multithreaded web server
The main thread creates worker threads to handle requests.
Example 2: Multithreaded text editor
The program creates a thread for each task that has to run in parallel.
Threads: Shared vs. Private Data
Threads in the same process share some resources, while others are thread-private.
Per-process resources
Address space
Global variables
Open files
Child processes
Pending alarms
Signals and signal handlers
Accounting metadata
Per-thread resources
Program counter
Registers
Stack
State
Threading Implementation
Threads are usually implemented as a thread table in the process control block.
POSIX API: Threads
Let’s have a quick look at the main functions of the POSIX API to manipulate threads:
int pthread_create(pthread_t *thread,const pthread_attr_t *attr,void*(*function)(void*),void*arg);
Create a new thread that will execute function(arg).
void pthread_exit(void*retval);
Terminate the calling thread.
int pthread_join(pthread_t thread,void**retval)
Wait for thread to terminate.
Note
You need to link the pthread library when compiling your programs, by passing the -pthread option to your compiler.
This allows programs to use the thread model on OSes that do not support threads
Scheduling can be performed by the program instead of the OS
It is usually provided by:
Programming languages, e.g., Go, Haskell, Java
Libraries, e.g., OpenMP, Cilk, greenlet
These runtime systems (programming language or library) must perform a form of context switching and scheduling.
Thread Mapping Models
The OS only manipulates its own threads, i.e., kernel threads, it has no notion of user-level threads.
Thus, user-level threads must be attached to these underlying kernel threads: this is called the thread mapping model.
There are three thread mapping models mapping user to kernel threads:
1:1
N:1
N:M
Thread Mapping Models – 1:1
Each user thread is mapped to a single kernel thread.
Every time a user thread is created by the application, a system call is performed to create a kernel thread.
Threading is completely handled by the OS, thus requiring OS support for threading.
Pros/Cons:
+ Parallelism
+ Ease of use
- No control over scheduling
Examples:Pthread C library, most Java VMs
Thread Mapping Models – N:1
All user threads are mapped to a single kernel thread.
Every time a user thread is created, the user runtime maps it to the same kernel thread.
The OS doesn’t know about user threads, and doesn’t need to support threads at all.
The runtime system must manage the context switches, scheduling, etc.
Pros/Cons:
+ Full scheduling control
~ Reduced context switch overhead
- No parallelism
Examples: Coroutines in Python, Lua, PHP
Thread Mapping Models – N:M
Multiple user threads (\(N\)) are mapped to multiple kernel threads (\(M\)).
Flexible approach that provides the benefits of both 1:1 and N:1 models, at the cost of complexity.
The runtime system manages the scheduling and context switches of user threads,
while the OS (kernel) manages the scheduling and context switches of kernel threads.
Pros/Cons:
+ Parallelism
+ Control over the scheduling
- May be complex to manage for the runtime
- Performance issues when user and kernel schedulers make conflicting decisions
Examples:goroutines in Go, Erlang, Haskell
Usual implementation
The runtime system statically creates one kernel thread per core, and schedules an arbitrary number of user threads on them.
User Threads and Blocking Operations
When multiple user threads share a kernel thread, they share the kernel threads’s state.
If a user thread performs a blocking operation, e.g., reading from the disk, all shared user threads are also blocked.
Two main ways of avoiding this issue:
Replace all blocking operations with asynchronous operations and wait-free algorithms.
This can be done explicitly by programmers, thus increasing the code complexity, or transparently by the runtime system or the compiler.
Rely on cooperative multithreading, similar to coroutines in language theory.
This type of user threads is also called fibers.
Scheduling
The Scheduler
Definition
The scheduler is the operating system component that allocates CPU resources to threads.
It decides which thread runs on which CPU, when and for how long.
The scheduling algorithm (or policy) used to take these decisions depends on:
The system itself, i.e., how many CPUs, how much memory, etc.
The workloads running on it, i.e., interactive applications, long running programs, etc.
The goals to achieve, i.e., responsiveness, energy, performance, etc.
Application Behavior
Each application has its own behavior depending on what it does.
But most of them alternate computations (on the CPU, ready or running) and waiting on IOs (blocked), e.g., waiting for data from disk.
There are two main classes of applications:
CPU-bound(or compute-bound): long computations with a few IO waits e.g., data processing applications
IO-bound: short computations and frequent IO waits e.g., web server forwarding requests to worker threads
Triggering the Scheduler
Depending on the applications’ and the hardware’s behaviors, the scheduler decides which thread runs on which CPU.
Application behavior:
When a process/thread is created ( \(\emptyset \rightarrow\)ready), i.e., after a fork()/pthread_create() \(\implies\)Does the parent or child thread run first?
When a thread terminates (ready/running\(\rightarrow\)X) \(\implies\)Which thread runs next?
When a thread waits for an IO to complete (running\(\rightarrow\)blocked), e.g., waiting on a keyboard input \(\implies\)Which thread runs next?
Hardware behavior:
An IO completes, triggering an interrupt and waking a thread (blocked\(\rightarrow\)ready), e.g., data request from the disk is ready, network packet arrival, etc. \(\implies\)Let the current thread run or replace it with the waking thread?
A clock interrupt occurs \(\implies\)Preemption?
Preemption
An important characteristic of a scheduler is whether it is preemptive or not.
Definition
Preemption is the ability of the scheduler to interrupt or suspend a currently running thread to start or resume another one.
In other words:
Non-preemptive schedulers choose a thread to run and let it run until it blocks, terminates or voluntarily yields the CPU.
Preemptive schedulers might stop a running thread to execute another one after a given period of time or a given event.
Categories of Scheduling Algorithms
Depending on the system, workloads and goals of the system, different categories of algorithms should be used:
Batch: Business applications, with long running background tasks (compute-bound) e.g., accounting, file conversion/encoding, training machine learning models, etc. \(~~~~~\longrightarrow\) Usually no preemption to minimize scheduling overhead
Interactive: Users are interacting with the system, or IO-bound applications e.g., text editor, web server, etc. \(~~~~~\longrightarrow\) Preemption is necessary for responsiveness
Real time: Constrained environments, where deadlines must be met e.g., embedded systems \(~~~~~\longrightarrow\) May or may not have preemption, as these systems are usually fully controlled, with no arbitrary programs running
Scheduling Metrics
Depending on the workloads, different goals are desirable for the scheduling algorithm.
In other words, the scheduler can optimize different metrics depending on requirements.
All categories
Fairness: Processes should get a similar amount of CPU resource allocated to them. Fairness is not equality, the amount of CPU allocation can be weighted, e.g, depending on priority.
Resource utilization: Hardware resources, e.g., CPU, devices, should be kept busy as much as possible.
Interactive
Response time/latency: Respond to requests quickly.
User experience: The system should feel responsive to users.
Batch
Throughput: Maximize the number of jobs completed per unit of time, e.g., packets per second, MB/s, etc..
Turnaround time: Minimize the duration between job submission and completion.
CPU utilization: Keep the CPU busy as much as possible.
Real time
Meeting deadlines: Finish jobs before the requested deadlines to avoid safety problems.
Predictability: Behave in a deterministic manner, easy to model and understand.
Example of Scheduling Policies
Now, let’s have a look at some scheduling policies!
Batch
First-Come First-Served (FCFS)
Shortest Job First (SJF)
Shortest Remaining Time (SRT)
Interactive
Round-Robin (RR)
Priority-based
Fair
Lottery
Real time
For each policy, we will give the following characteristics:
Runqueue: How are the ready threads stored/organized?
Election: What happens when the scheduler must choose a new thread to execute?
Block: What happens when a running thread becomes blocked?
Wake up: What happens when a thread wakes up from being in a blocked state to become ready?
Batch Scheduling: First-Come, First-Served
The First-Come, First-Served (FCFS) scheduler assigns threads to CPUs in their order of arrival, in a non-preemptive way.
Runqueue: Threads are stored in a list sorted by order of arrival, with the first element being the oldest
Election: Choose the head of the runqueue
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (at the end, like a newly created thread)
Event
Initial state
Election
\(A\) waits on an IO
\(A\) wakes up
\(B\) terminates
\(E\) starts
Running
\(\emptyset\)
\(A\)
\(B\)
\(B\)
\(C\)
\(C\)
Runqueue
\(A \rightarrow B \rightarrow C \rightarrow D\)
\(B \rightarrow C \rightarrow D\)
\(C \rightarrow D\)
\(C \rightarrow D \rightarrow A\)
\(D \rightarrow A\)
\(D \rightarrow A \rightarrow E\)
Pros
Easy to implement
Cons
With many threads, long latencies for IO-bound threads and high turnaround time for CPU-bound threads
Batch Scheduling: Shortest Job First
The Shortest Job First (SJF) scheduler assumes that a job’s run time is known in advance.
It works in the same way as FCFS, except that the job queue is sorted by run time.
Runqueue: Threads are stored in a list sorted by increasing total duration
Election: Choose the head of the runqueue
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (at its sorted position)
Example:
Let’s assume four tasks \(A, B, C\) and \(D\), arriving in that order and the following known durations: \(A = 5\), \(B = 3\), \(C = 4\), \(D = 3\)
Calculating turnaround time
Total turnaround time \(= a + b + c + d\)
Average turnaround time \(= \frac{4a + 3b + 2c + d}{4}\)
Policy
Total turnaround
Average turnaround
FCFS
15
10
SJF
15
8.5
Pros
Optimal when all jobs are known in advance
Cons
Does not adapt well to deffered job arrivals
Batch Scheduling: Shortest Remaining Time
The Shortest Remaining Time (SRT) scheduler is a modified preemptive version of SJF, where jobs are sorted by their remaining run time.
Runqueue: Threads are stored in a list sorted by increasing remaining duration
Election: Choose the head of the runqueue
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (at its sorted position). If it has a lowest remaining time than the running thread, preempt it
Pros
Short deferred jobs are not penalised
Cons
Long jobs can be delayed infinitely by new short jobs
Interactive Scheduling: Round-Robin
Round robin is a simple preemptive scheduler.
Each thread is assigned a time interval (quantum) during which it is allowed to run.
When a thread uses up its quantum, it is preempted and put back to the end of the queue.
Runqueue: Threads are stored in a list
Election: Choose the head of the runqueue. Election is also triggered when the running thread uses up its quantum
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (optionally refilling its quantum)
Example:quantum = 4ms; four tasks \(A, B, C\) and \(D\)
\(A\) is chosen as the head of the list to become running, with a quantum of 4 ms \(B\) becomes the new head, i.e., the next thread to run after \(A\)
\(A\) runs for 4 ms (using up its quantum), then gets preempted \(B\) is the new running thread \(A\) becomes ready and is put at the end of the queue
\(B\) runs for 2 ms, then waits on an IO (becoming blocked) \(C\) becomes running in its place \(B\) is not put back in the queue as it is not ready \(D\) will be the next scheduled thread
The IO \(B\) was waiting for is done, so \(B\) becomes ready again \(B\) is inserted at the end of the queue \(C\) keeps running until the end of its quantum
\(C\) finishes its 4 ms quantum and gets preempted \(D\) is the new running thread \(C\) is put back at the end of the queue as ready
Pros
Easy to implement, relatively fair
Cons
Quantum must be chosen carefully, requiring fine tuning
Note
The first versions of Linux used this algorithm.
Interactive Scheduling: Priority-based
Each process is assigned a priority, and the priority-based scheduler always runs the thread with the highest priority.
Priorities might be decided by users or by the system depending on the thread behavior (IO- or compute-bound).
Runqueue: Threads are stored in a list sorted by priority
Election: Choose the head of the runqueue (thread with the highest priority)
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (at its priority)
Example:Multilevel queueing (or MLQ).
An extension of MLQ is Multilevel feedback queueing,
where the system may change priorities to avoid threads hogging
the CPU or starvation, and assign a quantum to threads to improve fairness.
Pros
High priority threads are not hindered by others
Cons
Not very fair, may be complex to tune the priorities
Real life use
Linux used a variant of MLQ for years (the \(O(1)\) scheduler), and Windows still does.
Interactive Scheduling: Fair
A fair scheduler tries to give the same amount of CPU time to all threads.
Some may also enforce fairness between users (so-called fair-share schedulers), e.g., user A starts 9 threads, user B starts 1 thread, they should still get 50% of the CPU each.
Runqueue: Threads are stored in a list sorted by used run time (how they have used the CPU)
Election: Choose the head of the runqueue (thread that used the least amount of CPU time)
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue (at its sorted position)
Usually, these schedulers also weight the fairness, e.g., with priorities.
Example: The Linux scheduler (CFS, now EEVDF)
Pros
Fairness
Cons
Usually complex implementation, with a lot of heuristics
Interactive Scheduling: Lottery
A lottery scheduler randomly chooses the next thread running on the CPU.
The randomness can be skewed by giving more lottery tickets to higher priority threads.
Runqueue: Threads are stored in a list, not sorted
Election: Randomly choose a thread from the runqueue
Block: Remove the thread from the runqueue and trigger an election
Wake up: Add the thread to the runqueue
Pros
Very simple implementation, randomness is pretty fair
Cons
Low control over the results of the scheduling
Real Time Scheduling
Real time schedulers must enforce that threads meet their deadlines.
They can be separated in two classes:
Hard real time: Deadlines must be met or the system breaks e.g., the brake system of a car must respond to the pedal being pressed very quickly to avoid accidents.
Soft real time: Deadlines can be missed from time to time without breaking the system e.g., a video player must decode 50 frames per second, but missing a frame from time to time is fine.
Real time applications may also be:
Periodic: the task periodically runs for some (usually short) amount of time, e.g., the frame decoder of the video player is started every 20 ms and must complete in less than 5 ms.
Aperiodic: the task occurs in an unpredictable way, e.g., the brake mechanism of a car is triggered when the pedal is pressed and must engage the brakes in less than 1 ms.
Examples of real time schedulers: Earliest Deadline First (EDF), Deadline Monotonic, etc.
Recap
Recap
Processes
Abstraction that represents a program in execution.
It contains all the resources needed to run a program: memory, files, and threads.
Processes are isolated from each other, and do not share resources, unless explicitly done.
Threads
Entity that executes code within a process.
Threads share the resources of the process they belong to, but have their own state: program counter, registers and stack.
Scheduling
The scheduler is the OS component that allocates CPU resources to threads.
It decides which thread runs on which CPU, when and for how long.
Scheduling algorithms can be preemptive or not, and can be optimized for different workloads and goals.
Scheduling policies
Different scheduling policies exist, depending on the workloads and goals of the system.
They can be batch, interactive or real time.
Batch policies are usually non-preemptive, while interactive policies are preemptive.
Real time policies can be preemptive or not, depending on the system.


















































































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
_in_1936_at_Princeton_University.jpg#/media/File:Alan_Turing_(1912-1954)_in_1936_at_Princeton_University.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}